近日,Recurrent.ai 聯合創始人、XLNet 模型第一作者楊植麟,受邀在 CSDN 主辦的 2019 AI 開發者大會發表演講。在演講中,楊植麟首先從學術角度,詳細介紹了 XLNet 模型的核心設計思想和原理,然后站在創業者的角度,介紹了自然語言處理(NLP)在企業服務領域落地的四個技術階段。
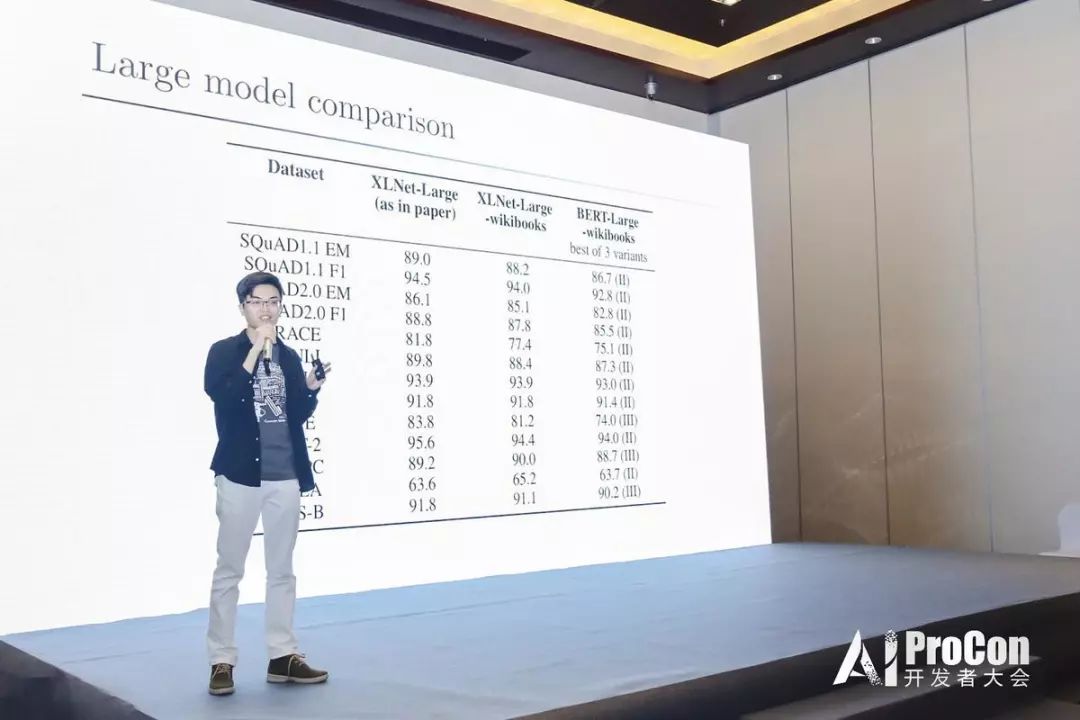
自從 2018 年 10 月 Google 發布 BERT 預訓練模型以來,NLP 領域的發展就進入了快車道。2019 年 6 月,楊植麟作為第一作者,由卡內基梅隆大學(CMU)與 Google Brain 團隊攜手推出的 XLNet 模型,在 20 項 NLP 任務中超過 BERT 模型,且在其中 18 項任務中拿到最優成績(State-Of-The-Art,SOTA),包括機器問答、自然語言推斷、情感分析和文檔排序等。XLNet 模型成為 NLP 領域備受關注的重要學術成果。
楊植麟在演講中提到,XLNet 論文已經被人工智能領域的頂級會議 NeurIPS 2019 接收為 Oral 論文,將獲得 15 分鐘的登臺演講時間。據了解, NeurIPS 2019 共收到 6743 篇論文,接收 1428 篇,其中 Spotlight 論文(5分鐘演講時間)164 篇,占比 2.4%;最重要的 Oral 論文僅 36 篇,占比 0.5%。
對于 XLNet 模型的原理,楊植麟介紹,當前 NLP 領域的預訓練方法可以分為自回歸(Auto-Regressive,AR)和自編碼(Auto-Encoding,AE)兩個陣營,XLNet 模型的核心設計思想是結合兩者各自的優勢,同時摒棄兩者各自的缺陷。
“XLNet 比較有意思的地方是,它在語言建模(Language Modeling)和預訓練(Pretraining)這兩種研究方向之間重新架了一座橋。過去,這兩種方向高度一致,更好的語言建模可以帶來更好的預訓練結果。但是當 BERT 這種雙向模型出來之后,情況變得不一樣,因為語言建模有個致命問題,只能對單向的上下文進行建模。”楊植麟分析道,“XLNet 模型把自回歸思想泛化,泛化之后的語言模型可以處理雙向上下文。因此,如果語言建模水平有提升,就可以將成果運用到預訓練過程中,從而在兩者之間重新架起一座橋。”楊植麟今年夏天從卡內基梅隆大學(CMU)博士畢業,博士期間他在 NLP 學術領域取得了多項世界級成績。在劍橋大學人工智能研究員 Marek Rei 公布的機器學習和 NLP 領域論文統計數據中,楊植麟連續入選 2017 年、2018 年頂級會議和期刊的第一作者排行榜,全球范圍內僅有 3 名學者能連續兩年入選。
在 NLP 學術領域碩果頗豐的楊植麟,選擇進入產業界,聯合創立了面向企業服務領域的 NLP 創業公司 Recurrent.ai。他如何看待 NLP 技術的落地?
“前幾年,在計算機視覺領域,新的模型算法刷榜之后,國內出現了一批獨角獸級別的創業公司。所以在 BERT、XLNet 等模型出來之后,很多人會問這些算法模型在產業界,會不會發生類似計算機視覺領域的事情,產生一批 NLP 領域的獨角獸公司。”針對現場很多人心中的疑問,楊植麟分享了他的思考,他認為 NLP 的落地需要經過四個技術階段,能否產生 NLP 領域的獨角獸公司,也就取決于誰能率先突破這四個階段的技術挑戰。
手動的、定制化的 NLP:基于規則、人工模型架構調優。
手動的、通用的 NLP:引入預訓練模型。
半自動的、通用的 NLP:引入 AutoML 實現自動調參。
自動的、通用的 NLP:將人整合為流水線的一部分,實現自動化。
“國內企業服務市場,大約 90% 的 NLP 技術處在第一階段。第二階段是將 XLNet 這樣通用的預訓練模型,用在不同的任務上面,只需要手動微調參數。第三階段是引入 AutoML 實現自動調參,將算法和模型自動化,這個階段對于做學術而言足夠了,因為數據集是現成的,但是對于產業落地還不夠。因為做產業時,拿到的數據就是未標注的,需要解決怎么標、標多少等問題。第四階段,就是把人(標注員)整合為流水線的一部分,如果需要擴展場景,只需要增加人力即可。”楊植麟詳細分享了他的看法。總結起來,楊植麟分享的 NLP 四個技術階段,就是從當前主流的“定制化開發”到“規模化量產”的必經之路。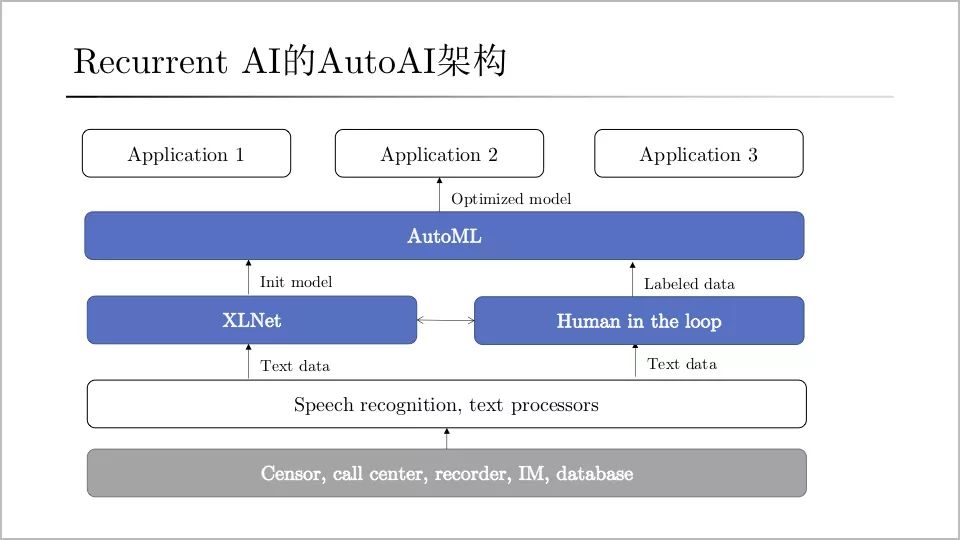
這也是 Recurrent.ai 正在做的事。楊植麟強調:“Recurrent.ai 所采用的 AutoAI 架構,最大優勢是底層架構是統一的,基于統一的底層架構,就可以規模化、可復制地支持不同類型的上層應用。”
楊植麟還分享了 Recurrent.ai 已落地的幾個典型應用場景:- 通過幫助企業分析銷售與客戶的海量歷史對話數據,進行銷售意向打分排序,提升銷售轉化率;
- 通過分析客戶咨詢的高頻問題及對應的高轉化回復話術,了解用戶心聲,通過調整溝通策略,提高意向客戶成單率;
- 通過自動結構化呈現客戶畫像,幫助銷售人員依據客戶的不同,使用定制的開場白,并且減少重復問題,進一步提升高分線索成單率。
“NLP 落地的最大痛點,從十年前到現在都沒有解決的問題,就是這個行業一直是高度定制化的。”楊植麟總結道,“而現在,隨著預訓練技術和 AutoML 技術的成熟,面向企業服務領域的 NLP 技術有機會實現規模化量產,只有實現規模化量產,才有機會誕生獨角獸級別的 NLP 創業公司。”
Recurrent.ai 核心產品提供基于客戶分析的AI銷售中臺,線索推薦系統、客戶心聲分析、智能質檢功能輔助業務增長,掃二維碼或閱讀原文申請免費試用!
























-620.svg)





