























-620.svg)


企業級ASR自訓練平臺 “諦聽”
基于原創的、先進的 Transformer-XL 端到端基礎模型,經過數百萬小時金融、房產、汽車等行業標注數據訓練,支持多場景的聲紋識別(角色分離)以及基于深度神經網絡的語音降噪技術,可為企業定制專屬模型。
-

模型自訓練
-

多場景聲紋識別
-

深度語音降噪
循環智能ASR和語音技術優勢
-

 原創底層算法模型
原創底層算法模型循環智能聯合創始人楊植麟與Google、卡內基梅隆大學,合作推出國際前沿的原創算法模型 Transformer-XL,并在全部六個主流語言建模數據集上奪魁。循環智能率先將該模型應用于企業級語音識別系統,實現準確率更高的端到端語音識別。
-
 深度定制化模型
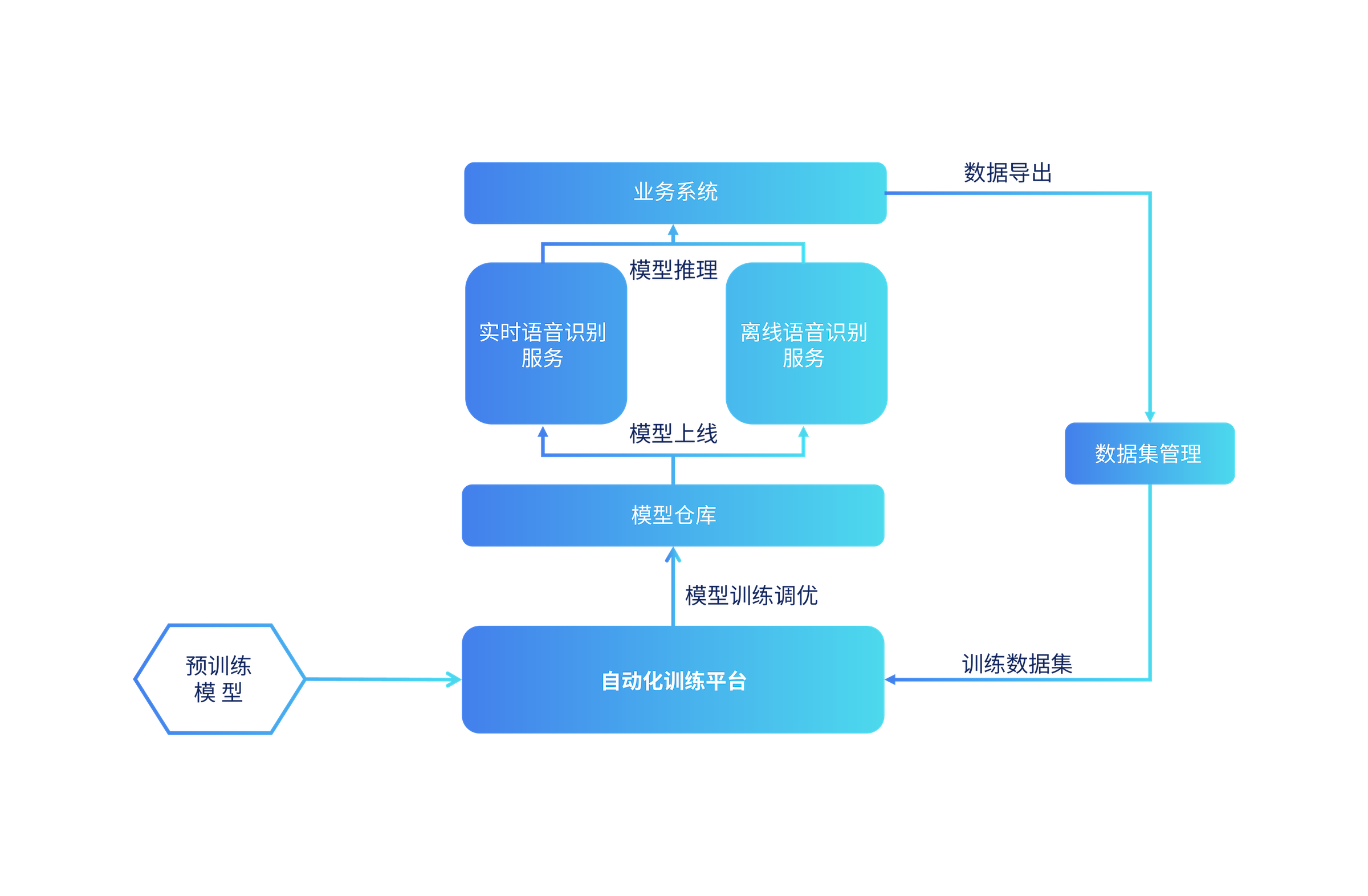
深度定制化模型提供從“熱詞”到“語言模型”和“端到端模型訓練”的多層次模型自訓練定制服務,可一鍵實現定制化ASR模型訓練。通過和業務系統打通,實現數據標注、篩選、導出、訓練閉環,并提供模型倉庫對模型版本進行管理,效果指標可追溯,一鍵部署上線。
-
 高精度角色分離
高精度角色分離因為節省存儲成本的考慮,很多企業采用單軌錄音。循環智能提供1:1聲紋匹配和1:N聲紋檢索能力,準確率90%+。在不指定說話人個數的情況下,可以準確的進行說話人角色分離,適應電話、視頻會議、線下溝通等各個場景。
-
 深度語音降噪
深度語音降噪傳統降噪方案無法應對復雜真實場景的非穩態噪聲和瞬時突發噪聲。循環智能基于深度神經網絡的降噪模型已適配數千小時上千種各類環境噪聲,可滿足各類使用場景。
-
 實時方言自適應
實時方言自適應在語音識別過程中,循環智能的ASR模型可以以句子為單位,實時判斷當前的方言和語種,并實時選擇最合適的ASR模型進行識別
-
 全棧AI語音能力
全棧AI語音能力不僅提供包括流式語音識別、長語義識別在內的語音識別算法,而且提供全套自研的全棧AI語音能力,包括說話人分離、聲紋驗證等聲紋相關算法、智能降噪和聲源定位等信號處理算法。
-
 自研麥克風陣列技術
自研麥克風陣列技術循環智能自研的麥克風陣列專利技術可以定向增強特定方向的聲音,過濾周圍的噪音;可同時對兩個方向進行波束成形,定向拾音,實現實時角色分離,滿足柜臺、會議室等線下場景復雜的收音需求,軟硬一體方案,即插即用。
-
 一站式語音數據接入
一站式語音數據接入在呼叫中心場景,提供旁路語音流、鏡像抓包、SIP代理三種接入方案,滿足不同IT架構需求;在傳統固化場景提供軟硬結合的方案,實現低成本的數字化升級;音視頻會議場景自研RPA方案;線下場景提供軟硬一體數據采集方案。
-
 支持私有部署
支持私有部署中小企業可以選擇 SaaS 模式,也可以選擇本地的私有部署或者云端的私有部署模式。我們將根據實際業務量,即每日電話錄音時長、實時轉寫的并發數,為您推薦高效的云端或本地服務器配置。


ASR自訓練平臺架構
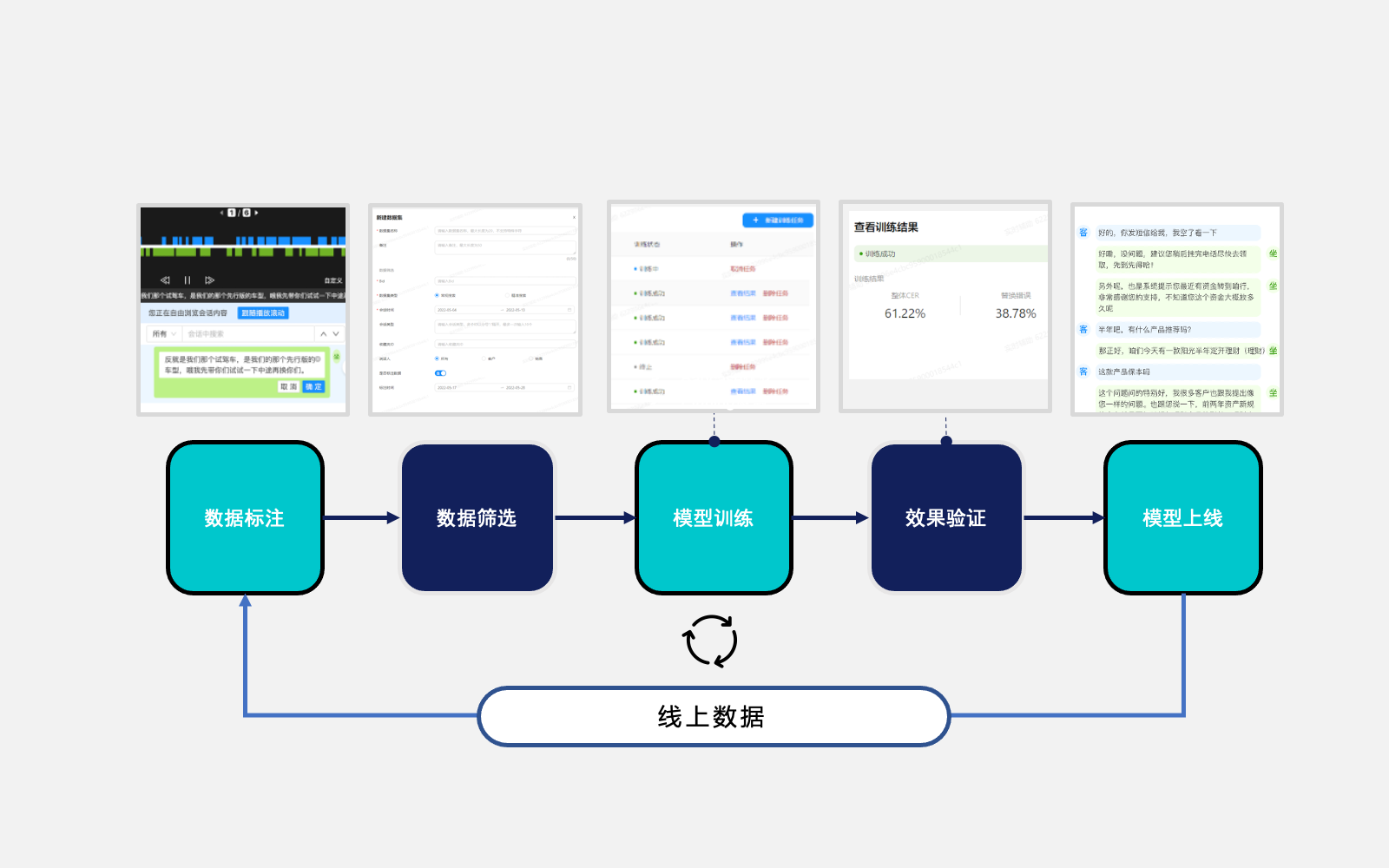
ASR自訓練主要流程
在技術專家、標注人員和運營團隊的通力合作下,借助標準化的ASR模型自訓練系統,可快速生產和管理定制化的ASR模型。
-
1
數據標注
-
2
數據篩選
-
3
模型訓練
-
4
效果驗證
-
5
模型上線
-
Step 1數據標注
人工標注修改基礎機器模型轉寫的文本
-
Step 2數據篩選
篩選已標注的數據,新建數據集
-
Step 3模型訓練
PTuning微調和Badcase優化
-
Step 4效果驗證
提供模型查詢、同步預測和異步預測接口
-
Step 5模型上線
選擇相應的模型上線正式使用

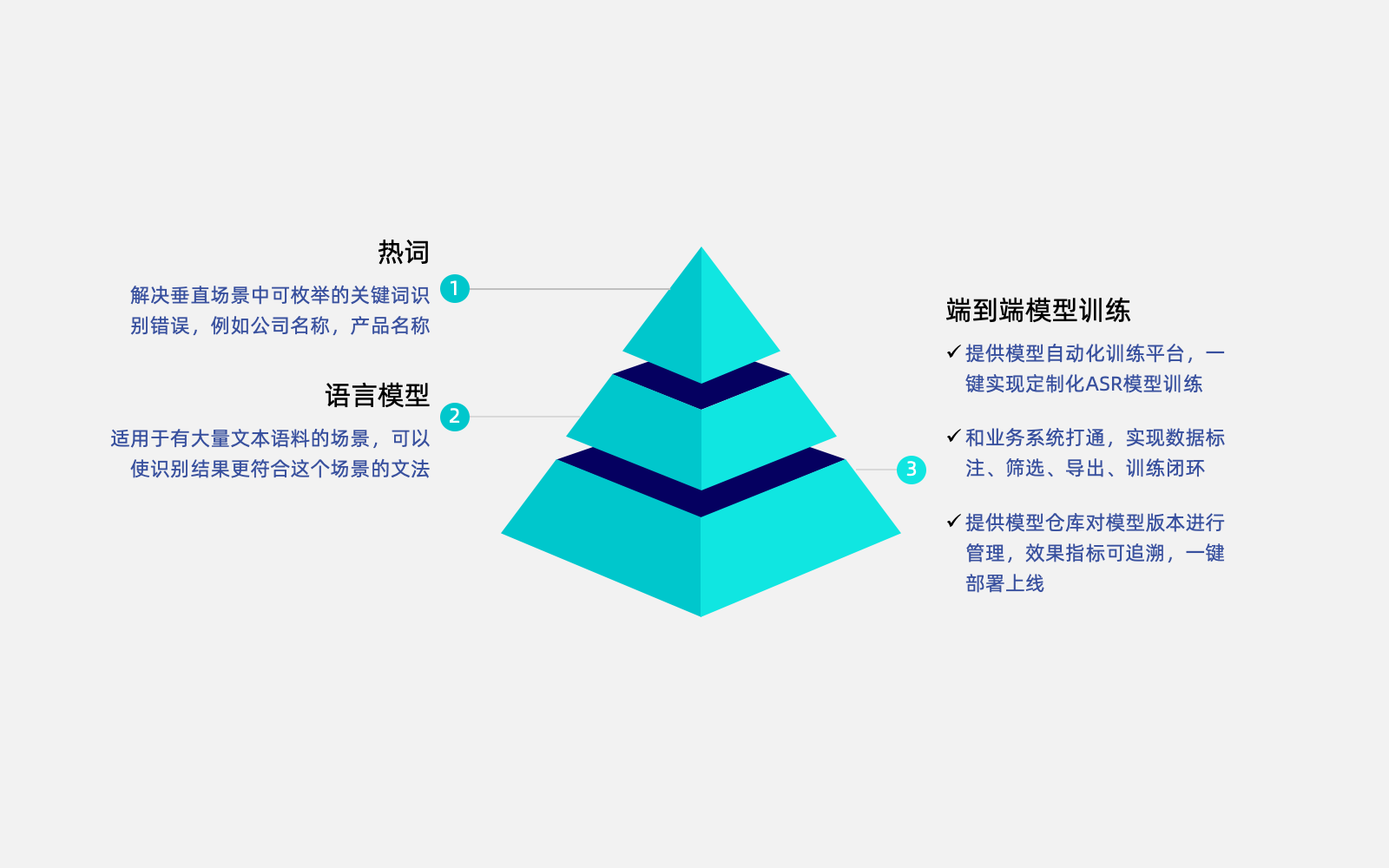
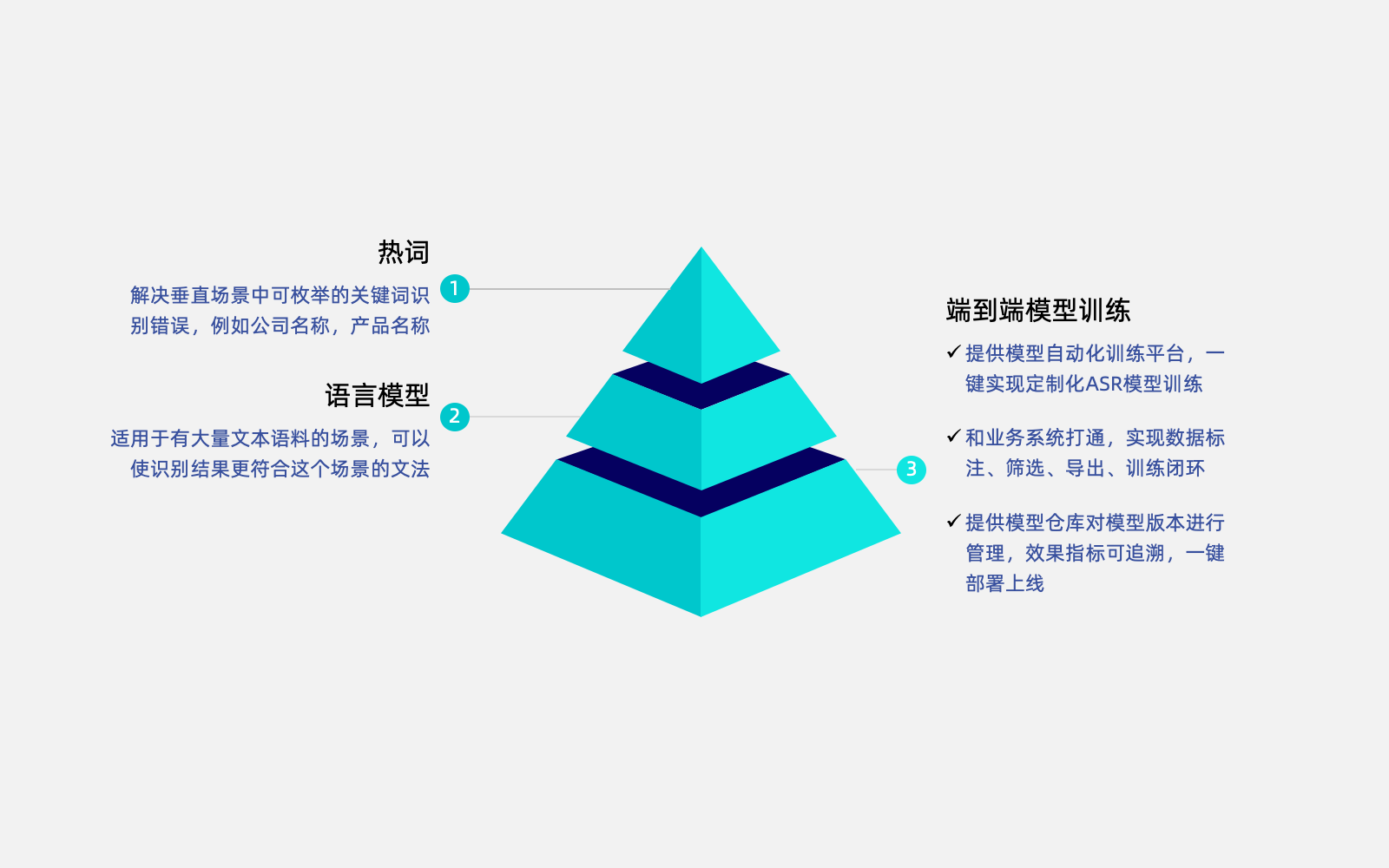
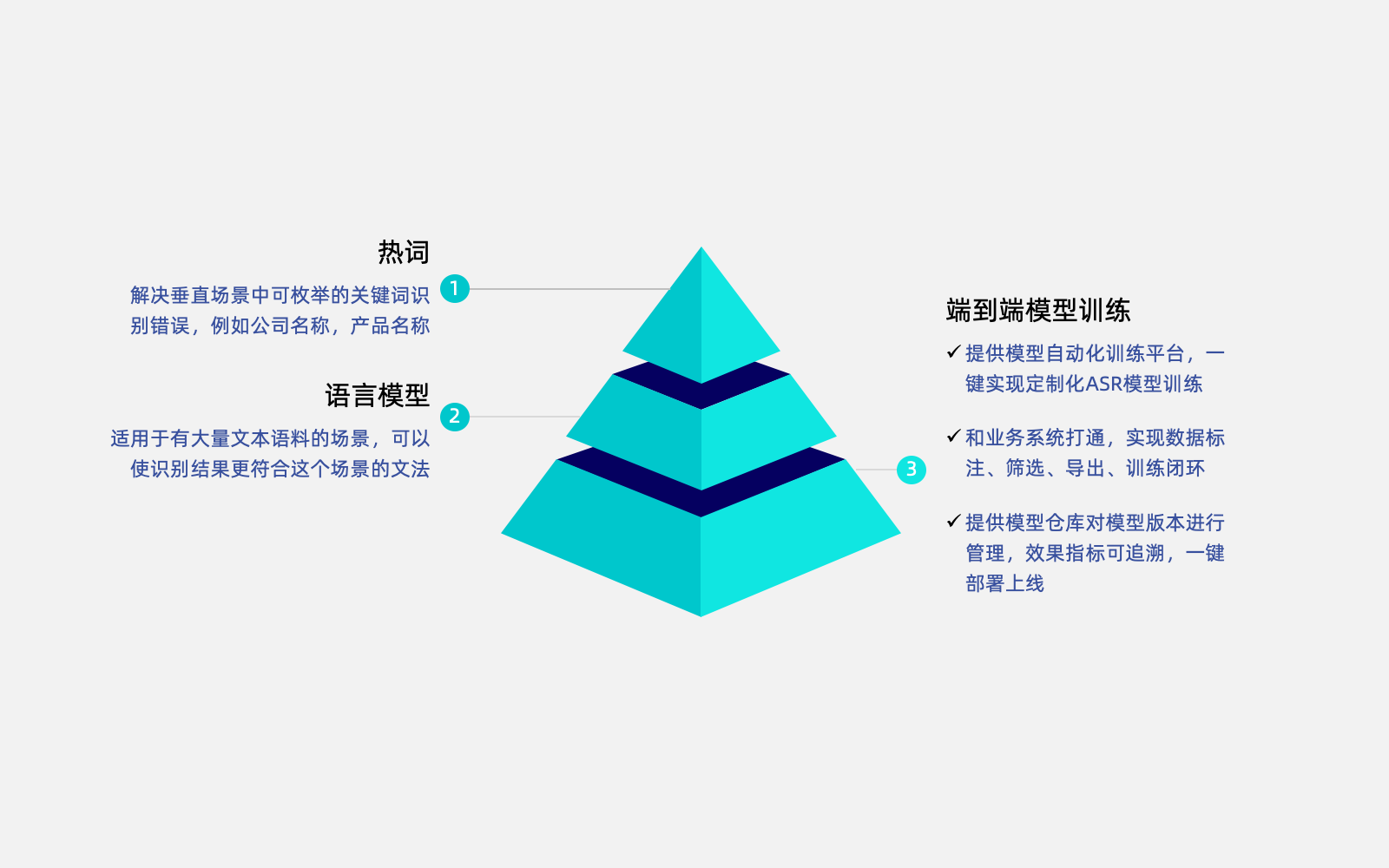
垂直場景ASR模型定制調優方案
針對業務需求提供三個層次的模型優化
-
 一、熱詞
一、熱詞解決垂直場景中可枚舉的關鍵詞識別錯誤,例如公司名稱,產品名稱
-
 二、語言模型
二、語言模型適用于有大量文本語料的場景,可以使識別結果更符合這個場景的文法
-
 三、端到端模型訓練
三、端到端模型訓練提供模型自動化訓練平臺,一鍵實現定制化ASR模型訓練
價值提升的適用場景
-
呼叫中心
提供旁路語音流、鏡像抓包、SIP代理三種語音流對接方案,可以適配不同IT架構的需求


-
金融柜臺
軟硬一體方案,場景專屬定制硬件,即插即用

-
會議室
基于自研硬件實現線下遠場錄音采集和語音增強,多角色分離算法,實現不指定人數情況下的準確語音分離

-
車內
使用基于神經網絡的語音降噪模型,可以在消除車內噪音的情況下盡可能完整保留對話語音

-
線下門店
利用麥克風陣列和聲紋相結合的技術,對語音進行降噪和準確的角色分離










眾多行業客戶的信賴










































提升你的銷售與客戶經營效率,就是現在
循環智能的解決方案專家可為您遠程或上門演示產品

