























-620.svg)


盤古NLP大模型
盤古大模型是業內首個千億參數的中文大模型,擁有1100億密集參數,經過40TB的海量數據訓練而成。同時也通過多任務prompt等技術延伸出10億參數、性能更好的落地版本,極大地加速了AI的商業應用效率和泛化能力;
盤古大模型的算法由循環智能主導和清華大學、華為的算法團隊聯合攻關,在預訓練階段引入基于Prompt的任務等多項創新方案,成功突破了大模型微調的難題。
-


多行業領域
-

多任務類型
-

中文大模型
-

零樣本學習
AI落地難的行業痛點
-
 標注數據量大
標注數據量大模型訓練所需數據量大,而數據標注依賴于昂貴的人工成本。

-
 研發成本高
研發成本高AI模型研發成本極高,開發、調參、訓練、優化均需專業的算法研究人員。
-
 優化周期長
優化周期長由于數據所需量大,標注周期長,嚴重降低了模型的迭代速度,效率非常低。
-
 泛化能力差
泛化能力差單個模型只可應對單個領域下的單個任務,業務種類多時,需多個模型來應對。
盤古NLP大模型的優勢
盤古的零樣本、小樣本學習能力強,可極大程度的減少數據的標注成本。
相比傳統調參方式,盤古通過自動化prompt的方式極大的加速了模型迭代速度,開發成本大幅降低。
由于不需要大量標注數據,且不用反復進行調參實驗,可實現盤古大模型的快速優化迭代。
盤古大模型可同時應對多個領域的多種任務類型,如金融、房產、教育等不同領域。
平臺采用全新的交互形式,設計簡約,流程清晰易懂,無需算法背景,通過擬人對話的形式創建并測試模型,簡單培訓后可迅速上手構建企業自己的定制模型。
-


零樣本學習
-

研發成本低
-

優化迭代快
-

泛化能力強
-

可快速上手




基于預訓練的NLP技術演進到第三階段
盤古大模型采用了最新一代技術,經過循環智能和華為的算法研究團隊的數月聯合攻關,通過Prompt將下游監督任務加入預訓練階段,
采用超多任務的大規模預訓練方式,大幅降低了微調難度,解決以往大模型難以為不同那個行業場景進行微調的難題。
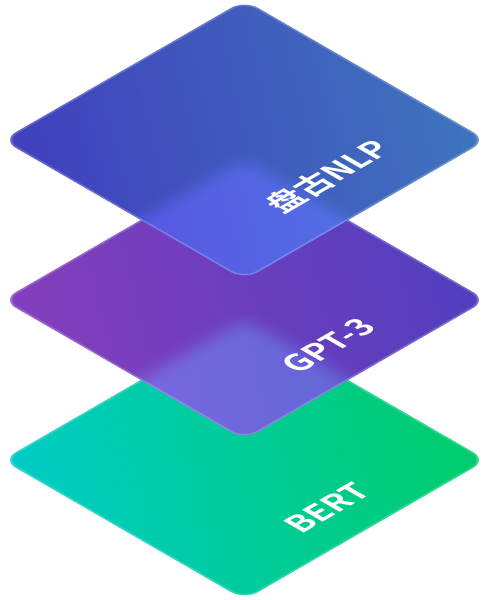
以盤古NLP大模型為代表的半監督預訓練+超多任務的大規模預訓練+自動化prompting

以GPT-3為代表的“超大規模預訓練+prompting”范式

以BERT為代表的“預訓練一微調”范式


超大規模模型帶來的流程變革




盤古NLP大模型的落地能力
聯系我們,即刻體驗盤古超能力
循環智能的解決方案專家可為您遠程或上門演示產品

