想必不少人都接聽過客服人員打來的電話。作為企業營銷及品牌價值宣傳的第一渠道,“呼叫中心”、“在線客服”、“客服機器人”等客服系統在新技術的催化下得到蓬勃應用。在金融、教育等對客服需求頗大的行業里,企業通過建立自己的客服團隊,向用戶推銷產品。
而另一個事實是,諸如“對不起,我很忙”、“謝謝,我們不需要”絕大多數用戶的婉拒和反感聲中,反映出客服行業面臨的諸多挑戰。AI技術的日趨成熟,如何更好地通過技術手段改善用戶與企業之間的溝通效率?如何提升銷售轉化?優化營銷業務流程?今年6月,一種新的NLP模型預訓練方法XLNet的推出,讓不少人看到了它的研究意義及落地價值。作為論文一作的楊植麟很快將該方法應用在了共同創立的公司循環智能(Recurrent AI)的業務線中。循環智能要解決的是,通過機器學習的方法分析原始的語音文字銷售過程和銷售轉化過程,幫助企業提高銷售轉化率。截至2019年8月,循環智能已服務二十余家中大型企業客戶。在創業初期,經過長達一年多的產品打磨周期,與其想要構建的競爭壁壘分不開。團隊在發展初期花了很長時間積累技術,2017年底有了一個比較成熟的模型。近日,雷鋒網(公眾號:雷鋒網)采訪了循環智能CEO陳麒聰、CTO張宇韜以及AI和產品負責人楊植麟,他們分別從業務、技術、AI產品的角度進行了闡釋。據官方資料介紹,循環智能主要提供的是一套智能化銷售系統,在客戶交互渠道如電話、IM中挖掘線索,主要有三大核心模塊: · 線索重定向,從企業客戶的CRM系統里尋找挖掘更多高意向用戶,提升銷售轉化率· 客戶心聲分析,將大量非結構化文本抽取出來,做批量高效的生產,分析和監測銷售溝通過程中的轉化漏斗和客戶畫像· 智能質檢,幫助企業客戶發現與用戶交互中的問題與風險循環智能在融合呼叫中心、CRM、BI等不同系統的同時,也在中間層搭建了語音、語義識別技術環節,以更好地支撐用戶數據。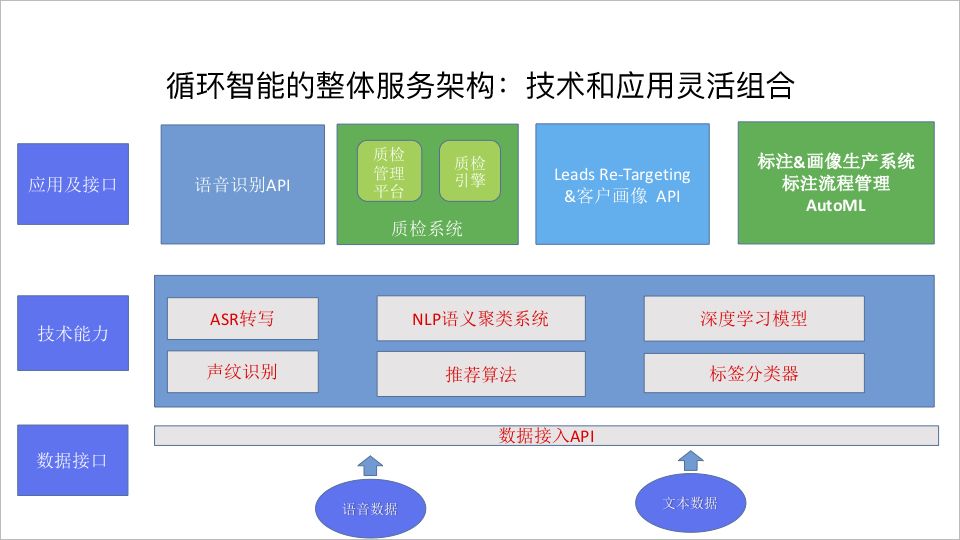
如上圖所示為循環智能的整體服務架構,當語音數據、文本數據流進入循環智能系統后,將在聲紋識別、語音識別、語義理解、標簽分類器等多個技術引擎中并行處理。例如,通過ASR轉寫,可以將一段語音轉化成文本;通過標簽分類器,可以得到由人工標注的分類訓練語料;通過語義的文本聚類,又能以無監督的學習方式組織文本信息。最終,不同技術引擎處理生成的數據,將依據不同訴求進行匹配和組合,進而形成可視化、高價值的數據,并以質檢、客戶畫像等產品形態為客戶業務做支撐。這個過程中,循環智能會分別跟呼叫中心、CRM、BI等上下游企業建立合作,將得到的非結構化數據“收集起來,同時進行分析”,從而轉化成一個結構化可消費的數據。不過,由于需要同時對接客戶不同渠道的溝通,復雜的CRM數據,以及一些客戶行為數據,這些數據往往分散在不同的系統里,如跟客戶的溝通在客服系統,跟銷售的溝通在呼叫系統,微信的溝通則發生在CRM上,這種做“重”的方式也直接導致了循環智能如何將這些數據高效打通的挑戰。循環智能會提供通用化API,用戶可以輕PaaS的方式完成整個工作流。“用戶只需要將原始的語音、文本等非結構數據聚合并通過API提交,就可以從產品界面直接對分析結果進行消費,無需關注其中的技術細節。”張宇韜解釋。在輸出產品的同時,循環智能構建的輕PaaS平臺,將整體技術封裝成業務中臺,能夠輸出整體的技術解決方案。相比之下,這個輕PaaS平臺更加聚焦于某個非常具體的行業或產品中,并非單純輸出ASR、NLP等技術。本質上講,針對不同行業提供的解決方案,用到的算法和技術是共通的,循環智能更需要做的是能力上的固化、產品上的下沉,并能夠將技術以打包的形式銷售給客戶。“傳統NLP是一個非常高度定制化、手動的技術,這也是我覺得直到目前NLP領域仍未出現獨角獸公司的原因之一。”楊植麟告訴雷鋒網。在此之前,循環智能也曾先后采用了多層的Transformer、以及BERT預訓練等技術方法。 循環智能希望能更多地專注在某個場景,并且這個場景能夠在不同的行業快速復制和規模化。實現這一目標的前提將在于如何更好地解決自動化和通用的問題。XLNet的出現,恰恰改善了在通用性上的問題。從原理上講,XLNet有效結合了自回歸方法(Auto-Regressive,無法對雙向的上下文進行建模)、自編碼(Auto-Encoding,預訓練和調優之間會有所區別的缺陷)兩種方法的優勢特征,將自回歸思想泛化,泛化之后的語言模型可以處理雙向上下文。可以說XLNet在NLP語言建模中很大程度上優于此前的BERT。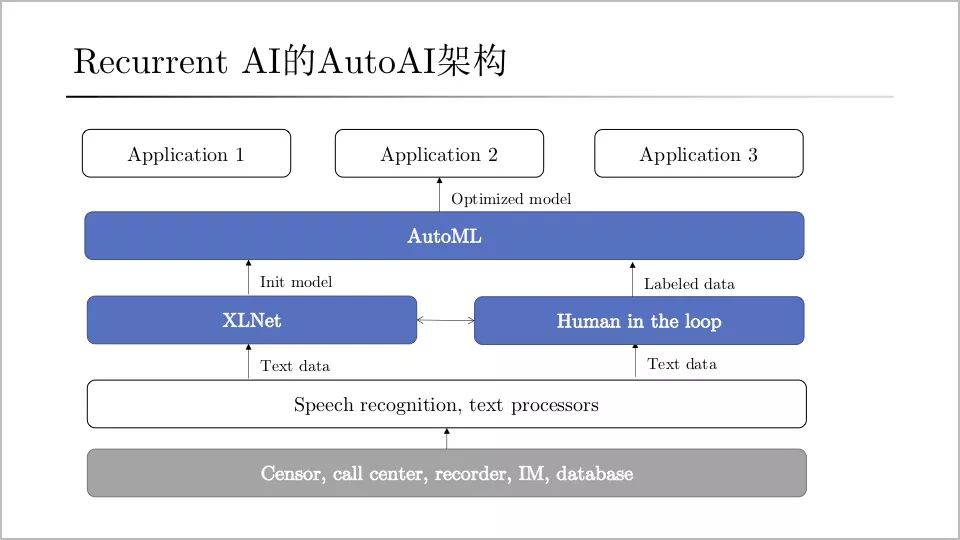
而在自動化問題上,循環智能還形成了一套AutoAI技術架構,其中包括兩個關鍵步驟:一是引入AutoML,無需手動調參;二是human-in the-loop,將人的數據作為整個生產流程里面的閉環。例如,標注團隊實時標注數據,標多少數據,是一套流水線,跟模型是統一的過程。在2019年6月XLNet正式推出之后,循環智能很快將這套預訓練方法應用于智能營銷系統上。據不完全統計,該系統可為企業線索池帶來 5%-10%的增量成單,分析并監測影響銷售漏斗轉化的關鍵步驟,提高15倍的質檢效率,進一步提升企業售前、售后、續費/復購整個流程的轉化效率。例如在催收行業,因其合規風險大,質檢成本高,工作量大,急需提高話術能力和客戶跟進策略等痛點,循環智能以極低人力復檢成本,完成了行業首例數千座席的全量質檢,還發掘了影響催回率的核心特征,在全量高度合規的情況下提高了企業用戶的催回率。對于這樣一支初出茅廬的團隊來講,取得這樣的成果實屬不易。盡管技術能保證創業公司在切入市場之初形成一定的先發優勢,但技術窗口期也是有限的。楊植麟認為只有6個月的時間。而在這短短6個月里,循環智能采取了更為“扎實”的打法:· 一是ToB領域軟件的替代成本很高,在一些成熟的行業里,不一定有機會。
· 二是設立長短期目標。短期目標是將智能化做到極致,而長期目標則是為相對傳統的公司提供數字化的服務。
不過就這個層面來講,AI技術本身在行業內是相對透明的,真正的核心價值是什么?三位創始人一致的回答都是:行業垂直數據,積累的know-how以及深度產品化的能力。截止目前,循環智能已累計標注了幾萬個小時的垂直行業語音數據,以及不同行業上百個語義點數據。為此,循環智能也將更多的精力投入在了產品和交付上。“客戶需求太多了!現在最主要的不是如何打動企業客戶,而是如何將企業客戶的需求進行交付。”陳麒聰強調。那么,如果對當前從事人工智能技術的創業公司進行劃分,有做平臺的,有做模塊的,還有做應用的,循環智能的定位究竟是什么?“我們是一個專注場景和產品的垂直性的公司。我們用一個小很多的模型就可以達到很好的效果,我們不希望也沒有必要去支持所有的領域,”這也更加表明,循環智能可能專注的能夠描述成:一些高客單價、獲客成本比較高、需要改善留存率、且天然存在非結構化數據的行業。此外,在某些線下場景如零售、4S店等,盡管沒有存量的非結構化數據,用戶仍有意愿采集這些數據。實際上,在客服場景,你所面對的客戶無非就兩種,一種是想要了解你的客戶,一種是已經付費的客戶。對于后者,客服的溝通可能主要是滿足客戶的咨詢和問題解決,但對于前者,銷售溝通的頻率高,客服在這個階段的價值體現也最為明顯。一種趨勢是,在企業客服的運營模式正從成本中心向利潤中心轉變的同時,“客服”這個概念也早已從原本純粹的客服轉變成為提高銷售轉化率的“助手”。或許,語音將是文本、圖像之后,企業數據挖掘的下一個價值洼地,而聚集了大量語音數據的客服系統只是一個切口。在NLP技術應用尚未成熟的背景下,如何打動用戶付費,挖掘市場更多的想象力,需要更多有勇氣的廠商前來實踐。對于循環智能而言,產品仍處于打磨階段,所以也必然會將產品市場匹配度(PMF, Product Market Fit)放在最優先級,將這款產品做成一個生態系統,并能夠在銷售的每個“溝通”環節里都有所滲透。這種邏輯或許也有效避免了與潛在對手的正面交鋒。(雷鋒網) ? THE END

循環智能的主產品是一個SaaS對話分析系統,針對銷售和客服場景,提供三大核心模塊,線索重定向、客戶心聲分析和智能質檢。掃二維碼申請免費試用!
























-620.svg)







