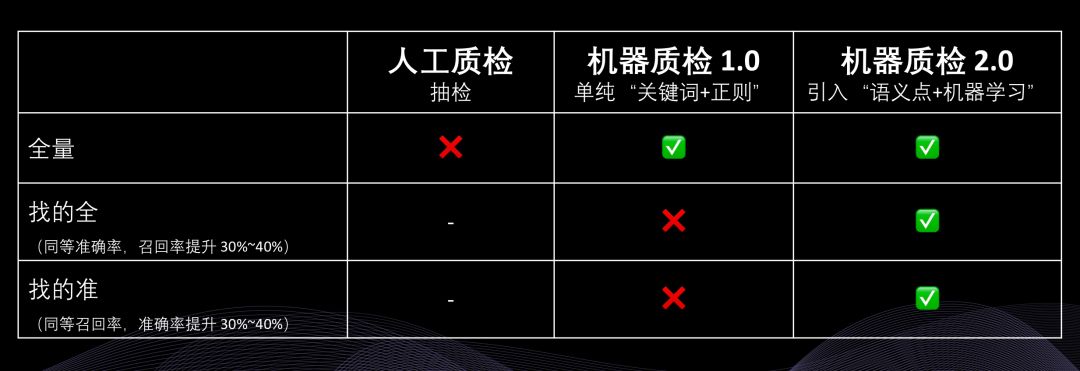
市面上有很多面向銷售和客服人員的語音質檢系統、文本質檢系統,絕大部分產品實際使用的是基于“關鍵詞+正則表達式”的機器質檢系統。
這種方法的主要優點是部署和上手使用都比較快,主要缺點是存在非常嚴重的漏檢情況。就像一個漏孔很大的篩子一樣,難以滿足企業對質檢的需求越來越精細、對質檢效率要求越來越高的發展趨勢。
因此,在“關鍵詞+正則表達式”之外,我們開始越來越多地為客戶提供基于“語義點+機器學習”方案,并且在實際使用中為很多質檢項帶來 2~10 倍的效果提升。也就是說,能夠多發現 2~10 倍的問題。對于企業而言,這就意味著他們可以更快、更全面地提升服務質量或者實現合規升級。

語音和文本質檢的主要任務是找出不合格、不合規的地方,即減分項,通常也被稱為“負向質檢”(另有一種任務是找出做得好的地方,即加分項,通常也被稱為“正向質檢”)。企業使用傳統基于“關鍵詞+正則表達式”的產品做質檢,所遇到的最主要問題是“找不全”,通常會漏掉很多不合格、不合規之處,導致質檢效率大打折扣。看一個實際對比的例子。某互聯網公司的基礎質檢項“服務態度問題”,在我們的實際應用中:使用傳統“關鍵詞”方案,一天的數據中能找出 13 條,100% 是正確的;使用新的“語義點”方案,能找出 134 條,其中 72% 是對的。所以從最終正確的條數來看,新的“語義點”方案多找出了 8 倍的問題。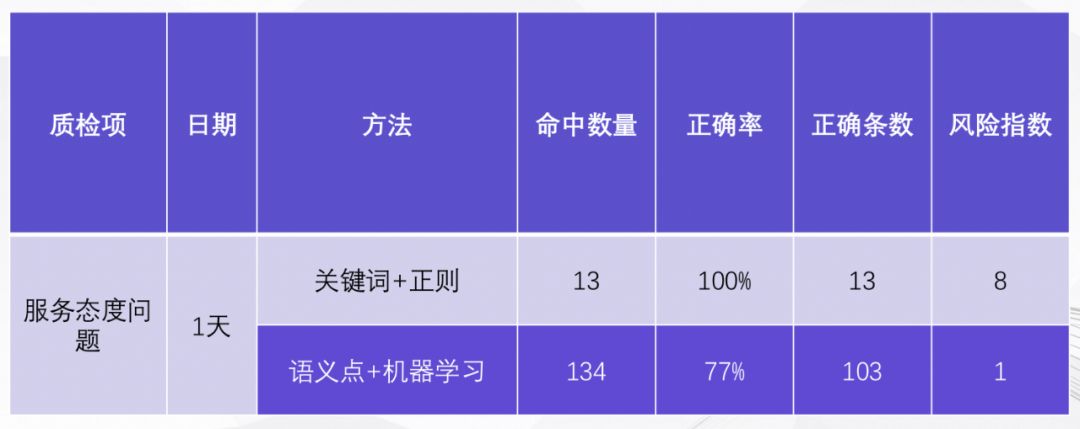
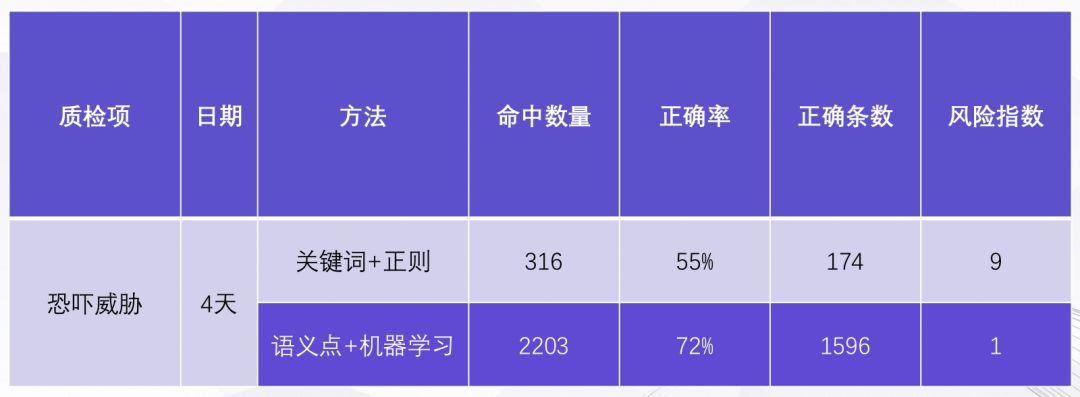
再看一個實際的例子。“恐嚇威脅”是貸后資產管理領域的基礎質檢項,即催收員不允許在電話里“恐嚇威脅”債務人。在我們的實際應用中:使用傳統“關鍵詞”方案,四天的數據中能找出 316 條,其中 55% 是正確的;使用“語義點”方案,能找出 2203 條,其中 72% 是對的。從最終正確的條數來看,174條對比1596條,新的“語義點”方案能多找出 9 倍的風險。原因其實很簡單。如果使用基于“關鍵詞+正則表達式”的方案,方法是用關鍵詞的組合來涵蓋每個質檢項的不同表達方式——但是你可以寫10個關鍵詞,100個關鍵詞,卻永遠不可能窮盡,因為語言的表達方式是非常多樣的、千變萬化的,必須通過整個句子的上下文語義才能做出更準確的判斷。
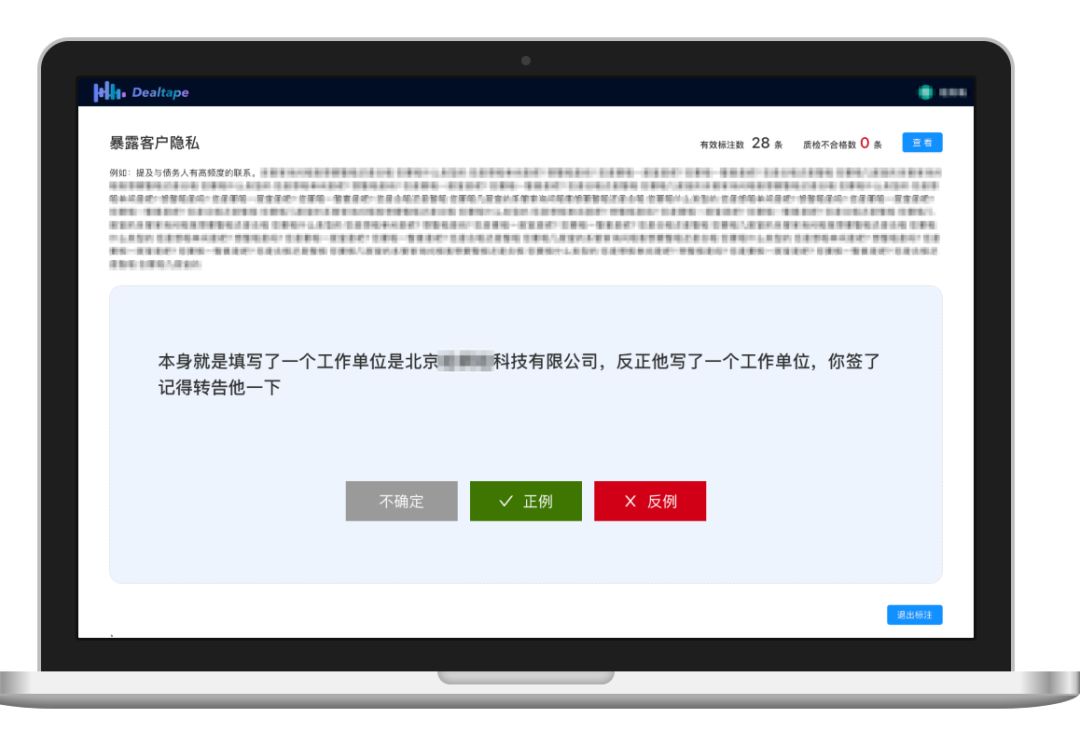
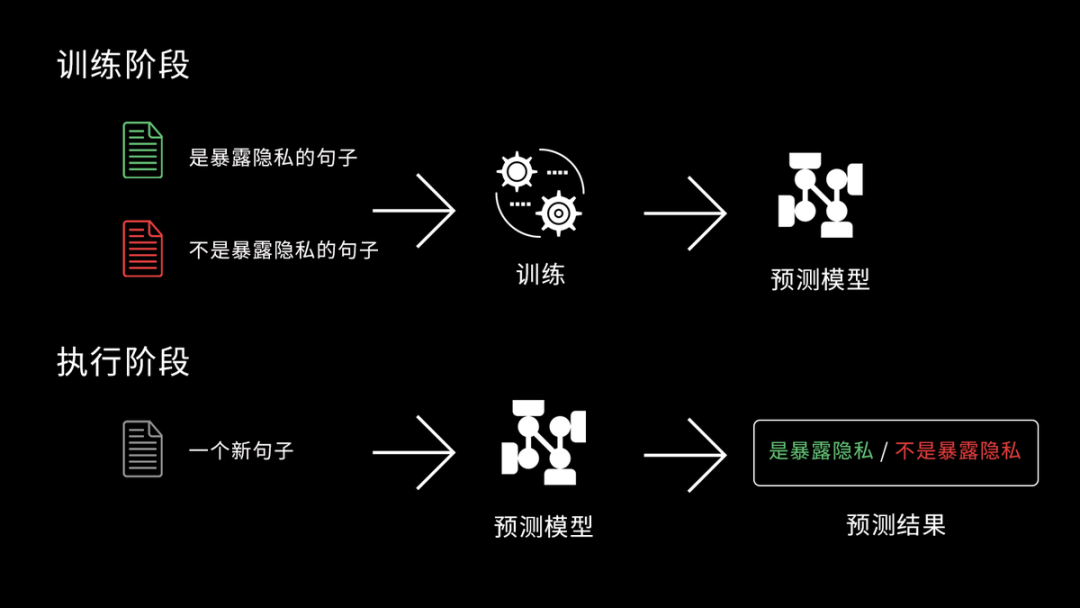
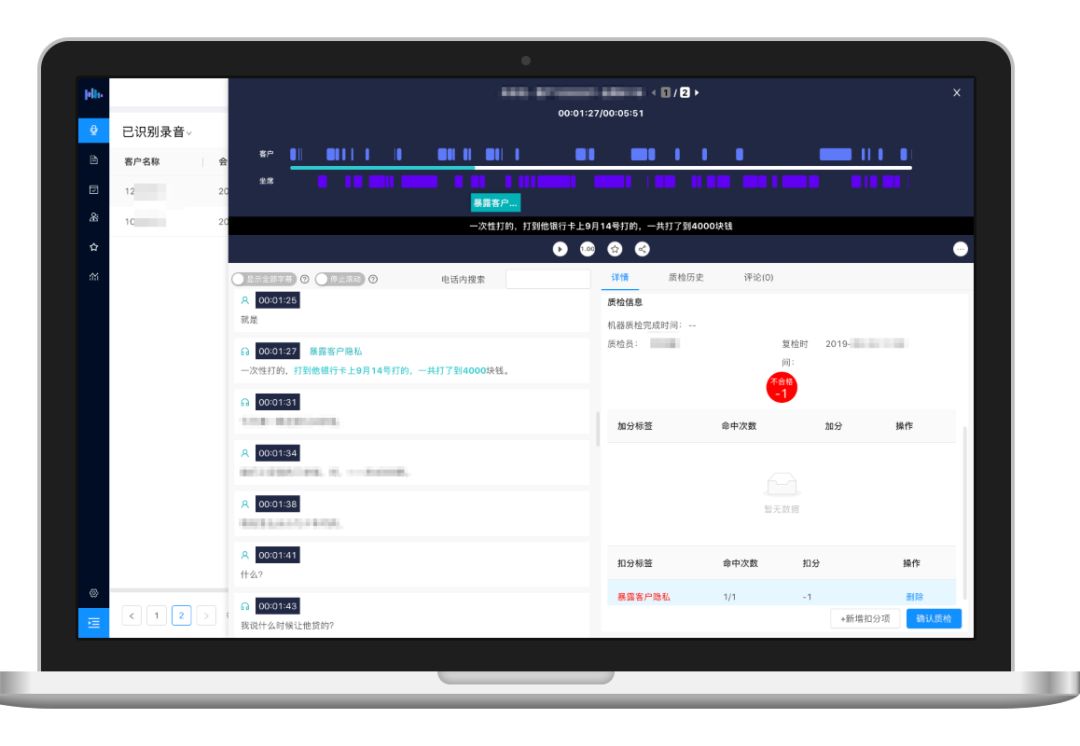
語義點+機器學習的方案,目標是訓練一個機器學習算法模型,使之能夠判斷關鍵詞未覆蓋的句子是否命中了質檢項。我們以另一個貸后資產管理領域常見的質檢項“暴露客戶隱私”為例。從標注到訓練模型,再到最后上線使用,新的“語義點”方案大致可以分為三個步驟。第一步,使用我們的“標注工廠”產品,通過人工的方式,將是“暴露客戶隱私”的句子標記為“正例”,將不是“暴露客戶隱私”的句子標記為反例。第二步,將一定規模的經過標注的正例和反例都“喂”給訓練器,讓訓練器學習到一個算法模型,這個算法就能用來判斷新句子是不是涉嫌暴露客戶隱私。第三步,在質檢產品中,系統就可以標記出所有命中“暴露客戶隱私”語義點質檢項的句子,復檢員可以快速定位到該質檢項所處的位置,迅速進行核實。此外,復檢員每一次復檢的操作,都相當于對算法模型進行了一次反饋,會幫助算法模型變得更準。最終,我們發現通過“語義點”方案能比關鍵詞的方案多找出數倍的不合格、不合規之處,達到召回率(找的全)、準確率(找的準)均在 80% 以上的效果。
從底層邏輯上看,基于“關鍵詞”的方案是字符級別的,并不關心句子的語義,而基于“語義點”的方案是句子級別的,非常關心句子上下文的邏輯和語義。兩者并不在同一個維度。可以想見,未來關鍵詞方案越來越難當大任,而語義點的方案會逐步成為主流。不過,語義點方案也有一個顯著的缺點“部署成本高”。為了訓練一個語義點的質檢項,需要人工標注大量句子,然后訓練和調試算法模型。因此,大家并不會立即就把所有質檢項切換到“語義點”方案,而是優先把那些最常見的質檢項切換到“語義點”方案。總結循環智能在教育、金融、互聯網服務等不同行業數十家客戶的服務經驗,我們發現質檢項與違規數的關系也存在“二八法則”——20%的質檢項貢獻了80%的違規數,所以將最常見質檢項升級到“語義點”方案,即可為整個業務帶來顯著的效果提升。同時,我們也應該了解到,隨著自然語言處理領域新技術的突破,從字符級“關鍵詞”方案,向句子級“語義點”方案轉換的速度正在加快。過去兩年,自然語言處理領域迎來了繁榮時期。Google 發表于 2018 年的 BERT 模型,為行業帶來了全新的技術思路,具有里程碑意義。2019年6月,作為 BERT 模型的一種重要的改進方案,XLNet 模型在 20 個標準任務集上超過 BERT,并且在 18 個標準任務集上取得 state of the art 成果,包括機器問答、自然語言推斷、情感分析和文檔排序等。

XLNet 模型由循環智能聯合創始人楊植麟博士(第一作者),與谷歌大腦、卡內基梅隆大學共同推出。該模型具備編碼超長序列的能力——簡單理解就是可以更好地理解長句子。2019年末,XLNet 被人工智能領域的頂級學術會議 NeurIPS 2019 接收為 Oral 報告論文(占比 0.5%)。同時,XLNet 也入選了權威的中國人工智能學會《2019人工智能發展報告》,被稱為 BERT 之后重要的進展之一。
循環智能(Recurrent AI)正是基于原創的、世界前沿的 XLNet 模型,在智能質檢產品中的加速向“語義點”方案轉換,取得遠超傳統方案的效果。過去一年,我們的智能質檢系統獲得多家金融、教育、互聯網服務領域贏得多家標桿客戶的商業訂單,包括眾安保險、玖富、CBC、華道、你我貸、人人貸、新東方在線、獵聘等。下一篇關于智能質檢的文章,我們將向大家介紹,在不同的業務場景下,關鍵詞方案如何與語義點方案高效搭配使用,大幅提升質檢效率。 ? THE END
循環智能的主產品是基于對話數據的 AI 銷售中臺,針對銷售和客服場景,提供三大核心模塊:線索成單預測、客戶心聲分析和智能質檢,并提供電話錄音ASR語音識別基礎服務。掃二維碼或點擊閱讀原文申請免費試用。↓↓↓
























-620.svg)