























-620.svg)


語音識別新范式:完全的“端到端”模型優勢在哪里?
-

2020-02-13
-

產品 · 技術 · 實踐


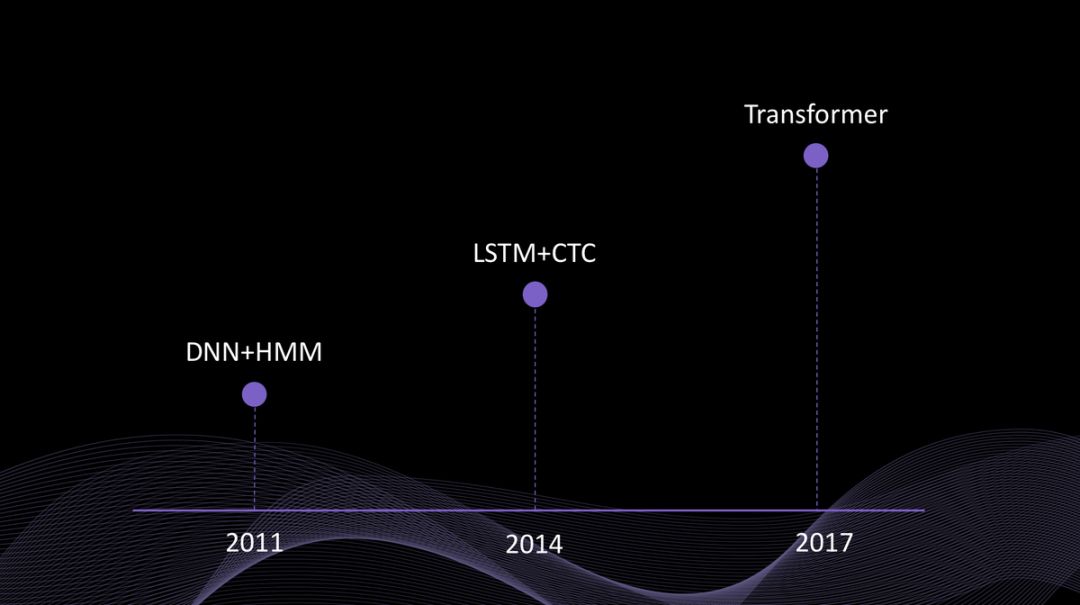
2011年前后,基于 DNN+HMM(深度神經網絡+隱馬爾科夫模型)的語音識別
2014年前后,基于 LSTM+CTC(長短時記憶網絡+連接時序分類)的不完全端到端語音識別
2017年前后,基于 Transformer(自注意力機制)的完全端到端語音識別
第一,Transformer采用的自注意力機制是一種通過其上下文來理解當前詞的創新方法,語義特征的提取能力更強。在實際應用中,這個特性意味著對于句子中的同音字或詞,新的算法能根據它周圍的詞和前后的句子來判斷究竟應該是哪個(比如洗澡和洗棗),從而得到更準確的結果。
第二,解決了傳統的語音識別方案中各部分任務獨立,無法聯合優化的問題。單一神經網絡的框架變得更簡單,隨著模型層數更深,訓練數據越大,準確率越高。因此企業可以使用更大量的專有數據集來訓練模型,得到相應場景下更準確的識別結果。
第三,新的神經網絡結構可以更好地利用和適應新的硬件(比如GPU)并行計算能力,運算速度更快。這意味著轉寫同樣時長的語音,基于新網絡結構的算法模型可以在更短的時間內完成,也更能滿足實時轉寫的需求。
2017 年 6 月,“Attention is all you need” 論文發表 ,Google 在這篇論文中介紹了 Transformer,一種基于自注意力機制(self-attention mechanism)的全新神經網絡結構。短短兩年多時間,該論文在 Google 學術中的引用量達 5956 次,毫無疑問是近幾年自然語言理解領域影響力最大的論文之一。
2018 年 6 月,Google 發布了基于 Transformer 的 BERT 模型,被稱為近幾年 NLP 領域最具里程碑意義的進展。
2019 年 10 月,Google 在官方博客中宣布,已經將這項技術應用于搜索中,增強了對用戶搜索意圖的理解。
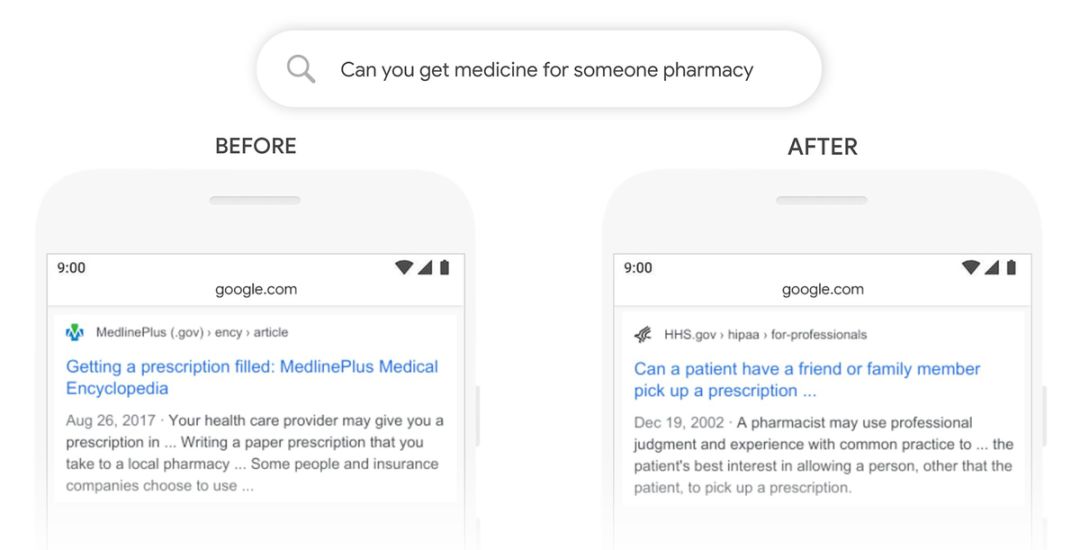
Google 搜索“可以幫人取藥嗎”的結果對比,新算法更準確地理解了用戶的搜索意圖,是想問能否幫人取處方藥。
? THE END

↓↓↓

