























-620.svg)


循環智能聯合創始人楊植麟:預訓練與微調的新范式
-

2021-03-24
-

媒體報道

2021年03月20日,北京智源人工智能研究院舉辦“智源悟道1.0 AI研究成果發布會”,發布超大規模系列模型“悟道1.0”的階段性成果。循環智能(Recurrent AI)聯合創始人楊植麟博士在會上代表“悟道·文匯”——我國首個具有認知能力的超大規模預訓練模型——團隊,做了主題為《預訓練與微調的新范式》的報告。
本次發布會上同時成立了由 9 位來自學術界和產業界的頂尖科學家組成的“悟道”大模型技術委員會。楊植麟博士與北京大學鄂維南院士、清華大學魯白教授、中國人民大學人工智能信息學院院長文繼榮教授等一道成為委員會成員,負責為大模型研發的技術方案和路線選擇等進行指導和把關。
超大規模預訓練語言模型仍需朝著多種不同方向進行探索。除了面向“認知”方向的“悟道·文匯”模型,循環智能還啟動了 NLP Moonshot 計劃,面向金融、教育、房產等 toB 產業應用方向,訓練超大規模中文預訓練語言模型,最大化 NLP 在產業應用的價值。

循環智能 NLP Moonshot 小組歡迎更多人才加入,推動技術在真實世界產生更大的影響力。
圖文回顧
楊植麟:之所以要做認知,和我們文匯小組的定位使命有關系。
第一,我們從一開始就想做有世界影響力的工作。不光是簡單地去復刻GPT-3或者BERT,而是在這基礎上創新,解決最難的問題,這可能是我們去做這個工作的意義所在。
第二,我們要探索智能的邊界。現在有不少超大規模的千萬億模型,但是很多問題是沒有辦法解決的,在認知問題沒有解決前,我覺得其實還是很有多的事情需要學術界和工業界一起探索和解決。
01
我們離認知還有多遠:通用、知識、可控
說到認知,我覺得可以簡單舉幾個例子。
比如說,我們能否有一個機器自動地閱讀產品需求文檔,直接寫出代碼,把需求開發出來?
或者,能不能有一個通用的對話機器人,通過語言的交互完成很多現實任務?
短期內要做到這些東西需要達到三個目標:
第一、通用。如果一個模型只能簡單地做一兩個任務,或者只能做特定類型的任務,我認為是沒有辦法實現認知。
第二、知識。如果模型沒有知識,在很多現實任務里就很難取得比較好的結果,很多現實任務需要結合知識才能做。
第三、可控。想讓模型完成一個任務,得有辦法指揮它,給這個模型一個明確地指令,讓它產生想要的狀態和行為。

長期目標,我們希望從預測去構造決策,包括完全解決少樣本問題,現在少樣本的很多任務上,實際上最好的方法,仍然跟我們使用大樣本的情況有很大差距,有時候是10個點,有時候是二三十個點,差距就會導致少樣本不能用,現在的模型無法建立一個完整的知識體系或者持續做這樣的學習,所以接下來做的事情是對預訓練和微調模式的創新,進一步接近認知目標。
今天想跟大家分享一下我們在這方面做的工作和一些最新的進展,主要集中在短期目標上,包括通用、知識和可控。

02
預訓練框架的通用性問題
通用,我們會從底層提出新的預訓練框架,去解決通用的問題,上層我們是用更好的算法,讓預訓練出來得到的模型,能夠去更好地挖掘里面的知識,以及更可控的去使用這樣的模型。首先我會講一講從通用的角度,預訓練框架如何提升。
相關論文 All NLP Tasks are Generation Tasks: A General Pretraining Framework 的主要貢獻者是杜政曉、錢雨杰、劉瀟、丁銘、裘捷中、楊植麟、唐杰。(論文地址:arxiv.org/abs/2103.10360)

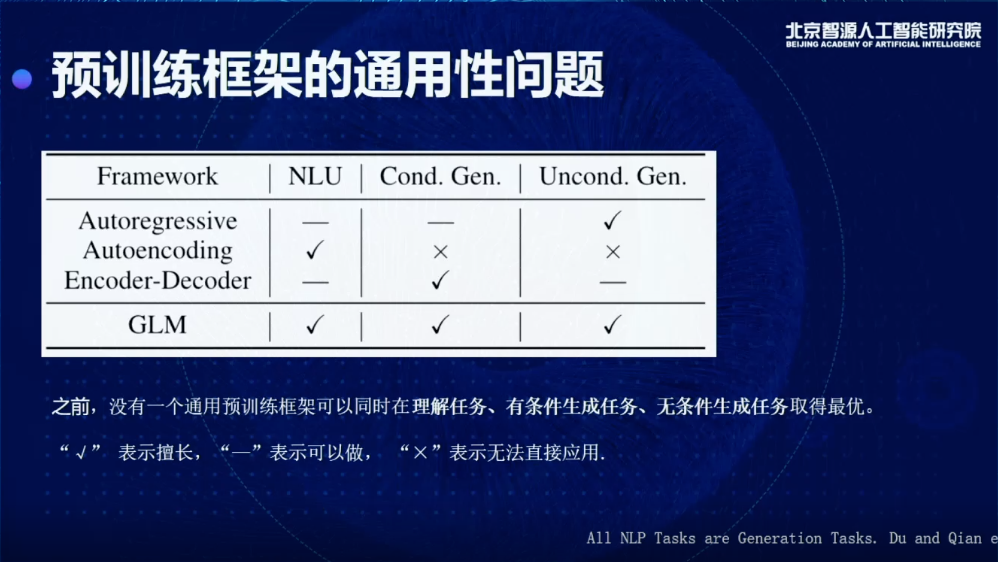
現在我們的NLP領域,主要解決的問題主要可以分為三類:
一種是基于分類或者理解任務,或者叫NLU任務,包括閱讀理解和情感分類,或者判斷兩個句子是不是同一個意思,會歸為一大類;
第二類任務,就是有條件的生成模型,比如想做一個摘要,或者想做一個翻譯,根據某種輸入,去對模型做一個微調,去生成我想要的東西;
第三種任務,是無條件的生成或者語言模型,在沒有經過繼續訓練的情況下,它可以持續的生成。
方法層面又分為三種:
一種是自回歸的模型,比如GPT,它的特點是非常擅長做第三類任務,即無條件生成任務,做有條件的生成任務,可以做,但是效果沒有BERT那么好,比如在Few-shot SuperGLUE上面,用一個GPT,1700億參數,最后做出來的效果,用2億的模型微調一下就會比它效果好,幾個月前有一個叫做PET的工作有這樣的數據對比,其他的數據集也可以觀察到這種情況,自回歸的模型其實做前兩個任務的效果不太好。
對于自編碼模型,最擅長的就是做分類理解的任務,但是生成基本完全不行。
還有一種是谷歌訓練新提出的,叫做Decoder-Encoder,比如T5模型。它的問題就是三個都可以做,但是至少有兩個做得不太好,分類理解和無條件的生成做得不太好。如果是一個非常高級的認知智能體,不可能只能做一個事情,其他的事情都做不了,好比建鋼廠,我們希望鋼做出來應用到很多的場景,而不僅局限于造一小部分的物件,所以這是我們整個工作的出發點。
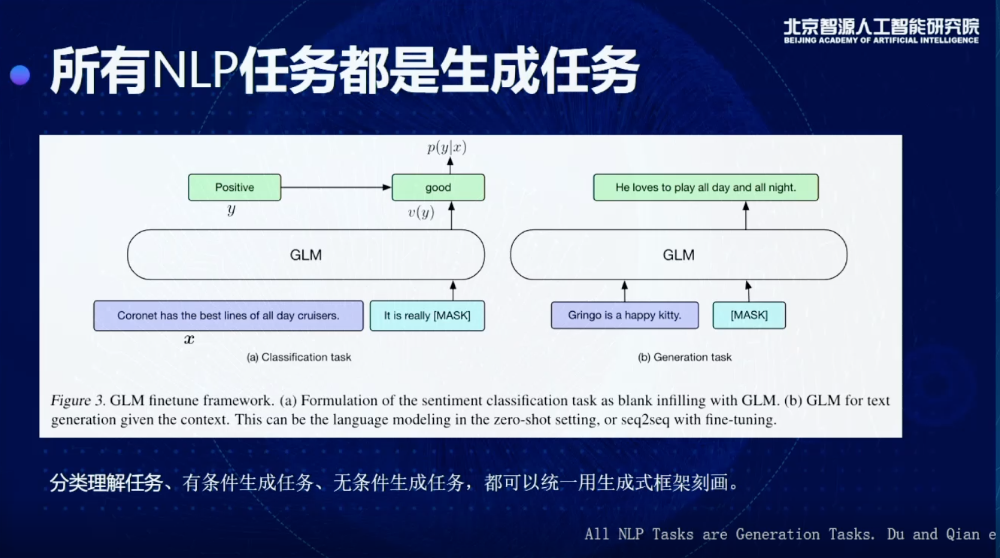
基于這個出發點,我們觀察到一個現象,就是幾乎所有的NLP任務都可以表達成一個生成任務。為什么呢?我們可以把三個任務做一個區分,有條件和無條件生成,可以被綁定到右邊圖的框架里(上圖),我給這個模型一個提示或者不給提示,讓它做生成,實際就是一個生成的框架。
比較難的問題是,對于這種分類和理解的任務怎么用生成任務定義,之前的工作提出了一些想法,其實可以把一個分類或者理解的問題,轉換成一個生成的問題。怎么做呢?比如說現在我想知道這句話的情感到底是正還是負,其實可以讓它去生成,比如說這個東西是good,就是一個正向的情感,如果是really bad,就是一個負向的情感,所以通過這種方式可以把所有的任務轉換成生成任務。
所有的任務都是生成任務,我們就可以在預訓練的時候,直接用生成的方式去做預訓練,生成的方式是我們在整個序列里面內嵌了很多Decoder,每次mask掉一些東西,通過在Encoder里面嵌入Decoder結構完成這樣一個生成。
同時我們也可以做多任務訓練,不光把中間的東西生成出來,還可以把末尾的東西,比如50%或者100%作為我們的生成目標,就可以同時去做很多不同的任務,也可以同時在很多下游任務上得到比較好的結果。

這是一個更具體的細節,比如說我現在給到一個輸入,x1到x6,我們會先做一個事情,這一步其實比較類似傳統的BERT做法,我們會從里面抽取一些我們的目標,比如這里抽出來的是x3、x5、x6,這三個,我會進行一個隨機打亂,比如把x5,x6放在前面,或者x3放在后面。
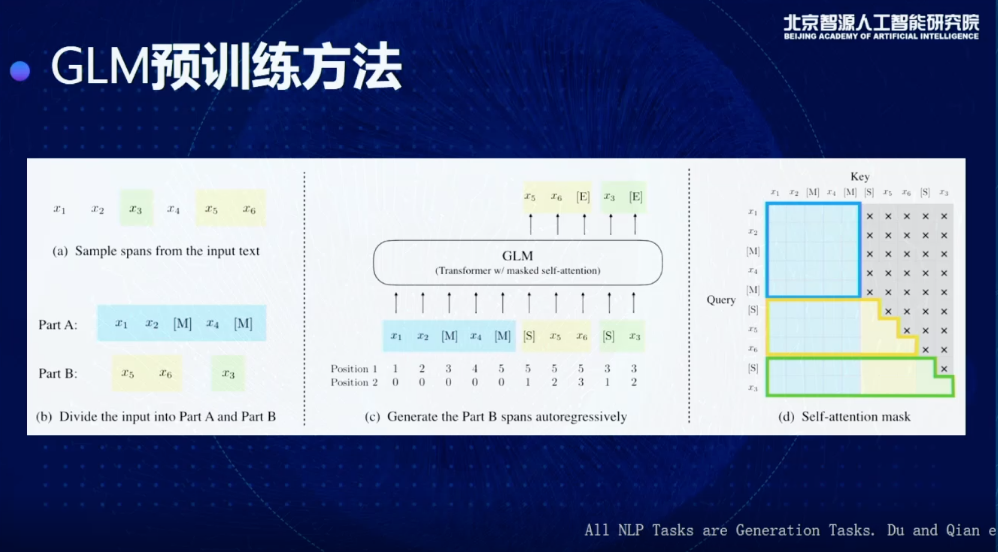
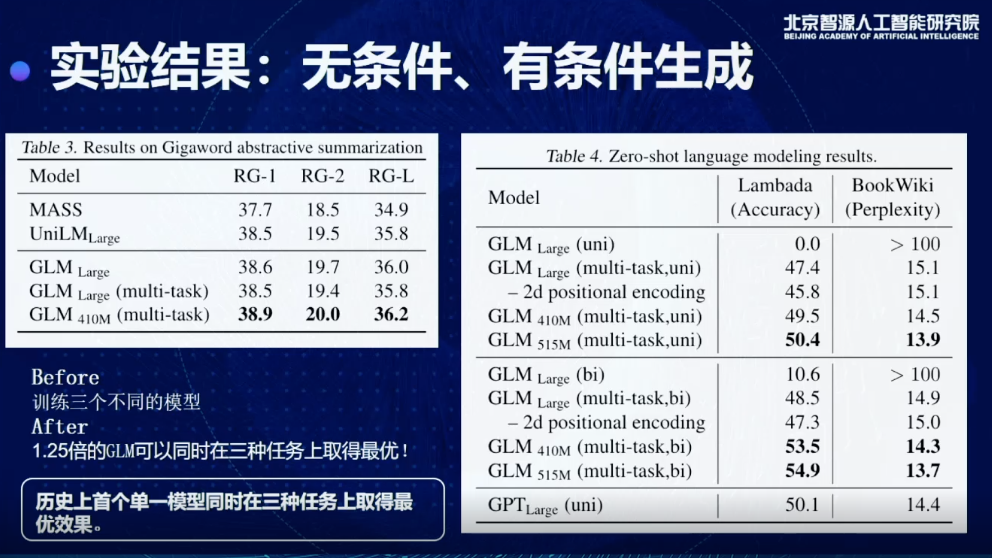
有了這個東西以后,我就去生成后面我想要的東西,通過加入position encoding和Masking的方法,相當于是在Encoder嵌入一個Decoder,這是在標準的SuperGLUE上得到的結果,我們會把所有的模型結果分為三類,這里面每一類都具有一個相似的訓練量,比如說 T5-Base,T5-Large,RoBERTa-Large,在一樣的訓練量情況我們做一個比較,就可以發現,雖然它是一個生成的模型,但克服了以前生成模型的一些缺點,可以在理解和分類任務上也取得更好的結果,特別是會比T5和RobERTa 得到更好的效果。
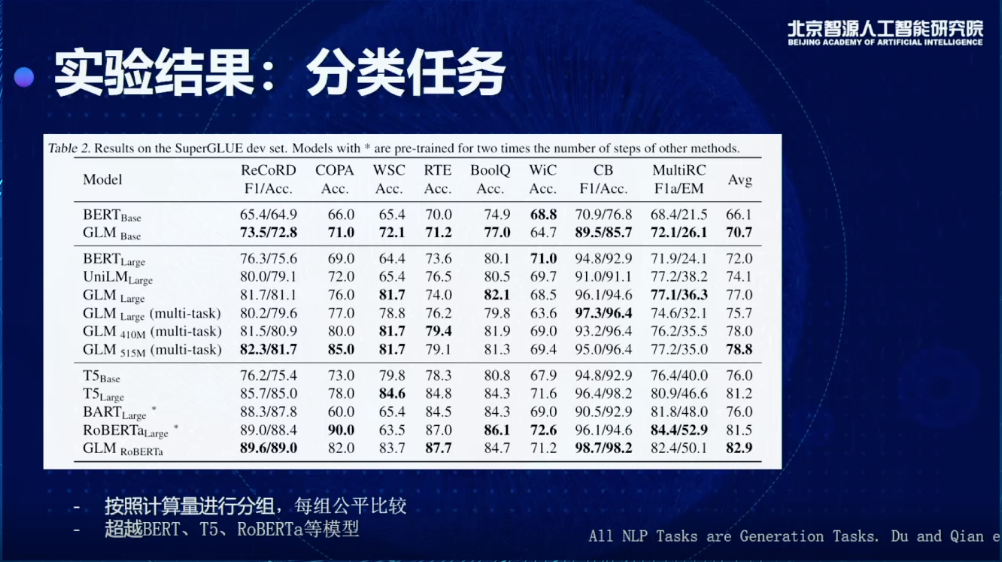
同時我們也測試了有條件無條件生成的情況下,會得到什么樣的效果,一個比較重要的結論,現在可以用1.25倍的GLM模型同時在三個任務上取得最優結果,以前要做,要分別訓練三個模型,對于超大規模來說也會非常限制模型的使用,這也是我們歷史上首次實現單一模型同時在三種任務上取得最優的效果。
03
預訓練模型如何做分類理解
講完了底層的通用預訓練框架,接下來會分享兩個新的方法,這兩個方法主要做的事情,就是當我有一個新的預訓練模型時候,怎么去最大化它的價值,去最大化的抽取里面的知識或者最大化地優化它的少樣本學習能力。

相關論文GPT Understands Too 的主要貢獻者是劉瀟、鄭亞男、杜政曉、丁銘、錢雨杰、楊植麟、唐杰。(論文地址:arxiv.org/abs/2103.10385)
首先要從Prompt說起,比如現在我可以給這個機器這樣的題目,比如X is located in Y,當X輸入London,我們希望它預測Y是一個Britain或者其他的東西,那么這就是一個Prompt。通過Prompt的輸入,可以實現少樣本學習或者知識抽取的能力,也是目前比較流行的一種微調的方式。其實很經常做的一個方法,就是用一個手寫的Prompt,相當于做特征工程,去做很多的嘗試,手工從數據里構造各種各樣的feature。

有了預訓練以后,這部分時間要去做Prompt engineering。要花很多時間手寫Prompt才能得到一個很好的結果,因為現在不同的Prompt只有細微的區別,有的只是增加減少一個詞,但是performance最后會差四十個點,甚至更多,所以這種方式是非常難適應很多場景,而且在很多真實的場景下,比如說少樣本學習的情況下,本來我們就沒有非常大的驗證集,就會造成一個問題,可能就是一個Over-fit的測試集,或者開發數據集,根本不靠譜。
后來,手寫變成自動,當然是一個進步,但是還不夠,始終是離散的,只要是離散的,就會面臨這種variance很大的問題。我們這里提出來想做的是,想用連續的向量,去表示Prompt,通過自動地學習Prompt去得到更好的結果。
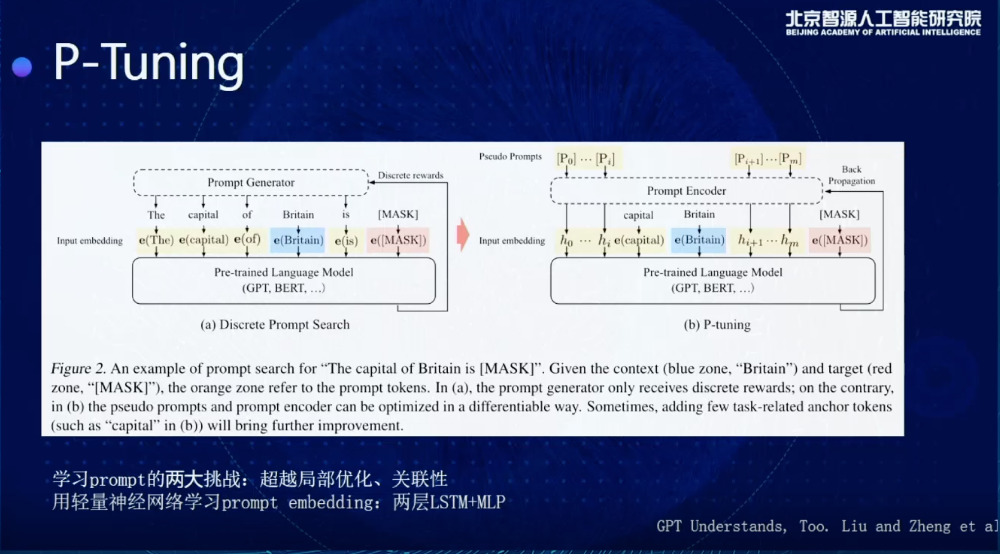
這是一個示意圖,展示了我們怎么去做這個事情。比如這里面Prompt是The capital of Britain is....,可以填一個國家的名字,讓這個模型告訴我英國的首都是哪里,傳統的話可能會有很多離散的Prompt Generator會去生成離散的Prompt,但是右邊,實際上可以用一個新的方法,給這個模型輸入很多連續的向量,通過連續向量輸入,直接在連續空間里尋找Prompt的最優解。
如果做到這樣,需要解決Prompt學習過程中兩個最大的挑戰:
一個是局部優化,比如我原來是學到了很多初始的embedding,我可以在embedding基礎上做很多微調,問題是通過SGD去優化,最多是在那個附近去震蕩,但是很難搜索到一個比較好的結果;
第二個,我們希望這些Prompt embedding之間有一個很好的關聯性,不希望每個獨立地去學,為了解決這個問題,我們會額外地加一個Prompt encoder,不光去學一個trainable vector,加兩層LSTM,加一個NLP,同時解決局部優化和關聯性的問題,取得一個比較好的結果。
這個是我們在知識探測的任務上得到的一個結果,目前我們是最好能夠做到64%,這個模型預訓練完以后,在測試階段不給他任何額外的文本,它不需要任何文本,它不是傳統的知識抽取,我只要模型訓練完,就直接從里面獲取知識,這個benchmark,大概一年前,它的最好結果是20多,你抽出來的知識里,只有20%是對的,大概幾個月前,大家優化到40左右,現在通過我們的方法,我們可以做到60%多,也就是說我現在這個模型在不給他任何額外文本的情況下,我就可以抽取出來60%多正確的知識。
這個里面,我們可以看到幾個對比,比如說MP指的是我去手工寫Prompt,P-tuning就是自動連續去調的方法,通過對比這兩列,可以發現會有一個非常大程度的提升,比如在MegatronLM(11B)數據集上可以提升41個點,用RoBERTa-large可以去提升30多個點。

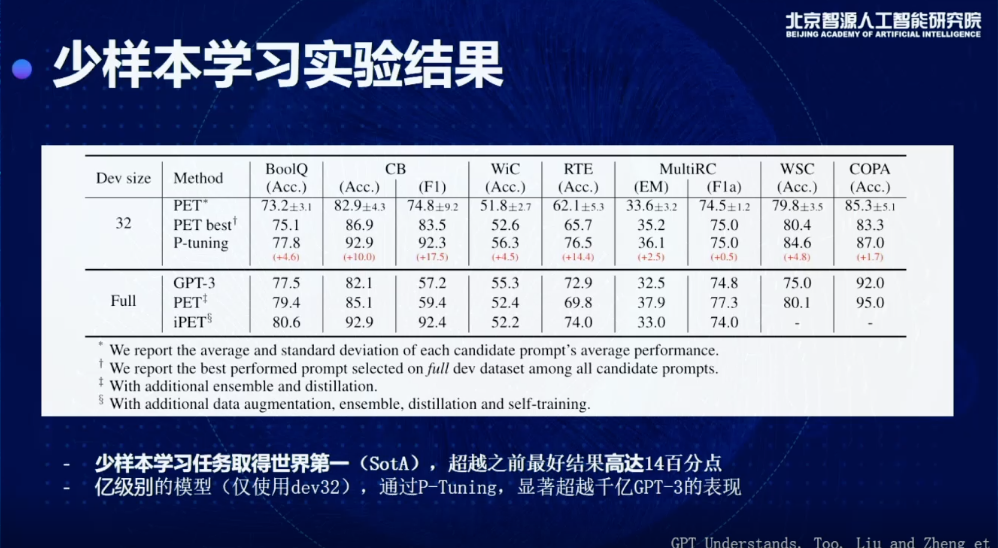
另一個問題,少樣本學習非常重要而且也有非常廣泛的工業應用,研究的是怎么通過少量樣本,比如說20、30個,你就能夠學到一個任務,而且這個任務的結果,和比如用一千兩千甚至一萬個樣本可以得到到差不多的結果,實際上我們把這種應用放到很多NLP生產系統上,就可以極大程度地提升效率。
目前我們也是通過P-tuning的方式可以在Few-shot SuperGLUE上取得一個SOTA的結果,而且相比之前的方法,最高提升14個百分點,而且需要注意的是,我們現在用的模型,是個億級別的模型,它只有幾億個參數,但它的效果已經比GPT-3在大部分數據集上有一個提升,GPT-3需要強調的是,當時開發的時候要用到完整的驗證集,并不是真正的few-shot learning setting。我們這個是標準的few-shot learning的setting,在這種情況下,我們可以打敗之前包括PET和GPT-3在內的所有few-shot learning的SOTA方法。
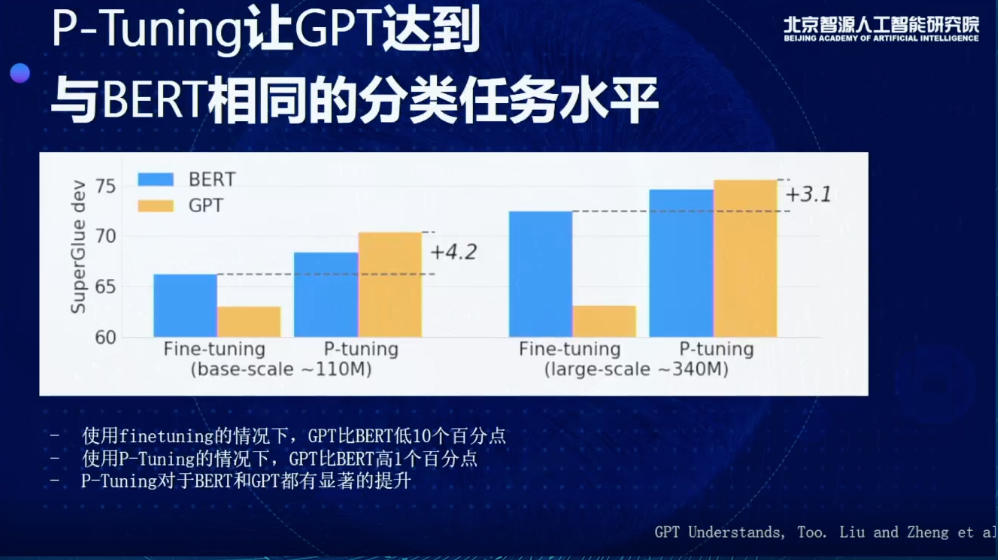
另外有趣的是,這個模型抹平了GPT和BERT在分類理解任務上的差距。由圖可見,藍色的是BERT的結果,橙色是GPT的結果,左邊是Fine-tuning,右邊是P-Tuning。當我們在用Finetuning的時候,不管是哪種scale,BERT都會非常明顯比GPT更好,可能會好10個百分點。而使用P-Tuning的情況下,GPT會比BERT高1個百分點,且P-Tuning對于BERT和GPT都有顯著的提升。
這大概是我們的第二個算法,主要是解決預訓練模型怎么做分類理解任務。
04
基于Inverse Prompting的優化
第三個工作,Controllable Generation from Pretrained Language Models via Inverse Prompting,我們想分享的是在生成的時候可以做到可控。這個工作主要的貢獻者是鄒旭、殷達、鐘清揚、楊紅霞、楊植麟、唐杰。(論文地址:arxiv.org/pdf/2103.10685)

這里,我們從知乎摘了一個問題,去問我們的模型,說什么瞬間讓你想留住這一刻?生成的句子非常通順,但是實際上并沒有在回答這個問題,也就是這個問題和答案關聯性非常弱,這是一個普遍存在于預訓練語言模型中的問題。

為了解決這個問題,我們就提出了一個新的方法,通過這個方法優化以后會生成:
一瞬間想到高二的時候,那天下午在操場曬了一中午太陽,和同學一起在樓下打球,下午的夕陽徐徐灑下來,我們三個人一起站在走廊上,倚著欄桿可以面對著夕陽。一直想留下那一瞬間,可惜我以后再也沒有遇到過那樣的時光。
這個回答還有點淡淡的憂傷。通過這種優化可以讓回答和問題關聯性更強,可以更好地通過Prompt控制所生成的內容。這是一個技術思路,核心的思路就是用生成的內容反過來用同樣的模型預測原來的Prompt,這樣的方式就可以保證這兩個東西之間的關聯性更高。把原來的Prompt的likelihood當成一個分數,在beam search的時候去重新rank里面每一個beam的分數,就可以實現這樣的效果。
有了這個東西以后,我們發現它可以實現一些非常神奇的效果,這些效果可能以前的模型很難做到,比如我用現代的概念作古體詩。一般的語言模型能做的事情就是擬合一個文本,都是現代或都是古代的。但通過Inverse Prompting的方式可以把兩種概念糅合到一起,這個模型真的可以捕捉到對象里面核心的特征,通過古體詩表達出來,特別是最后一句,若非王氣起天壤,世界繁華豈易名,這跟我們當前的世界格局有一些關聯。

下面這首詩寫的是虹橋機場,這是非常現代的概念,古詩里從來沒有,如果我學一個古詩的語言模型,根本不可能作出這樣的詩,這首詩讀來有一種孤獨感和憂傷感,當然從詩歌專業的角度肯定會有一些瑕疵,但是你可以感受到非常深刻的孤獨感,包括和虹橋、夜非常貼合,會有燈、月映水簾星、盧浦這樣的意象。

還有詠相對論,引力張鞭勢,牯牛曳著行,營造了一種科技感的氛圍。

也可以寫一些藏頭詩,在beam search時可以固定藏頭字,而且當你輸入白話風格的標題時,它作詩的風格會相應地變化,帶有強烈諷刺意味。

也可以回答問題,比如你問人注定要死為什么還活著?
它給了一個比較正面的回答:
我們活著的意義就是要尋覓人生的價值,體驗生命的壯麗。為了追求這種生活,人們愿意奮斗終生。

這只是一些案例。最后我們還是要從量化的角度評估效果到底怎么樣,所以我們找了很多人去看這個生成的結果,你就會發現相比于只用Prompting Baseline,分數會有很多提升。
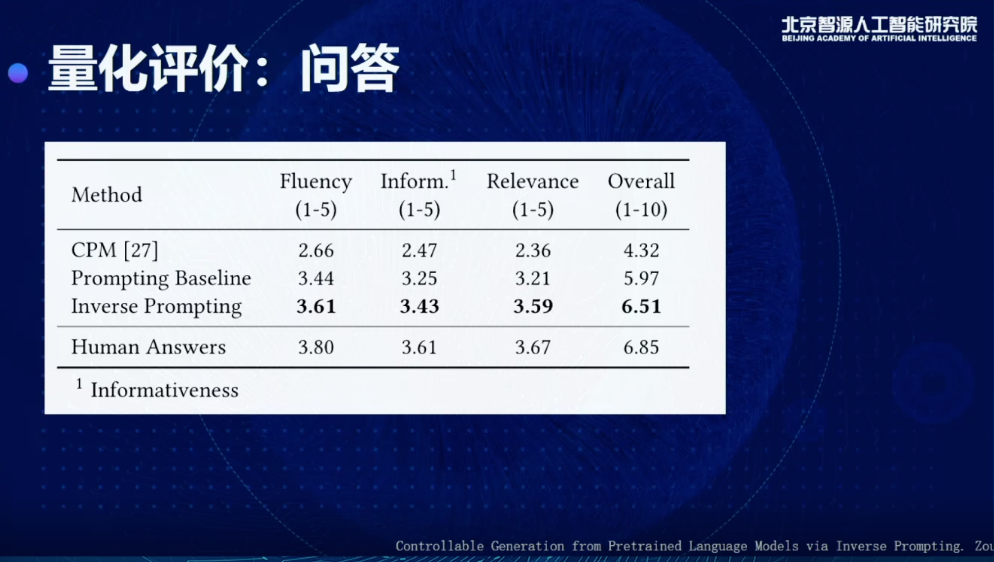
作詩上,我們從學校里找了詩社的人,讓他們來衡量。和之前非常有名的九歌系統(Jiuge)做對比,發現各有千秋。九歌系統在韻律題材方面有一些優秀的地方,整體的評分會比搜索和Prompting這種基礎方法有很大提升。
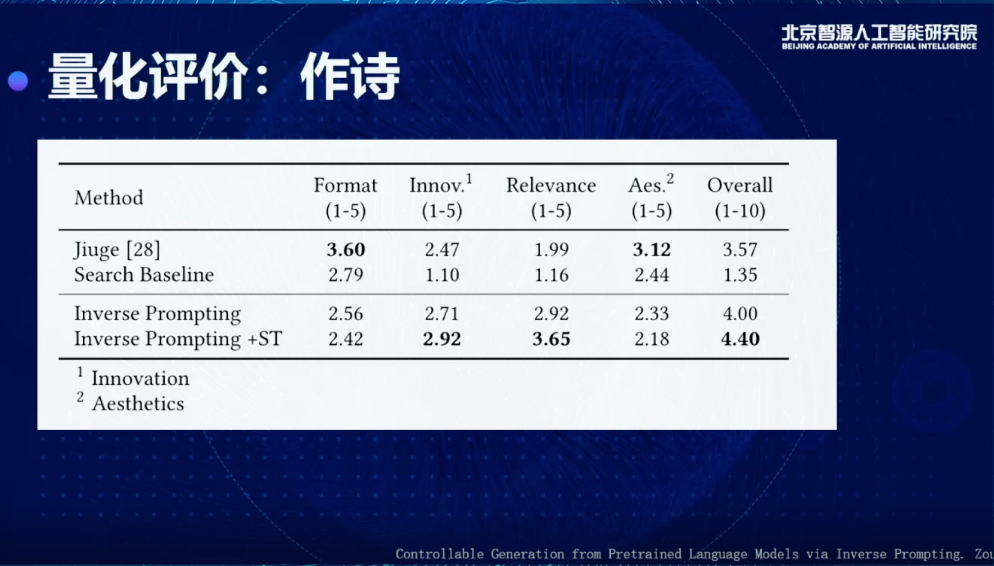
正如唐老師介紹的,我們還做了圖靈測試,找了很多古代詩人真正寫的詩,用它的標題去生成一些詩,可以看到有45%得票率,比較接近古代大師人的作詩水平。
總結
我們其實從三個方面,從技術的角度去做了一些突破,包括通用、知識和可控三個方面,從算法的層面去做了一些提升。長期來看,這三個算法只是第一步,往后還是要從更長期的角度解決問題,包括怎么去做決策,怎么真正完全少樣本,以及這些代碼系統怎么融合起來,去解決更多更難更大的問題,這都是未來要思索和探討的方向。
? THE END
關于循環智能
循環智能(Recurrent AI)是一家 AI 企業服務公司,借助原創的自然語言處理和深度學習技術,幫助中大型企業充分挖掘對話數據的價值,提升員工產能,帶來業績增長。公司服務的客戶主要在保險、銀行、房產和在線教育等領域。創始團隊來自清華大學、卡內基梅隆大學,并獲得紅杉資本中國基金、真格基金、金沙江創投、靖亞資本等知名投資機構的支持。2020年,循環智能獲得高新技術企業認證,并被德勤Deloitte評選為中國明日之星50強。2019~2020年,循環智能連續兩年入選《機器之心》年度最具產業價值榜單。
循環智能
增強“人”的智能
銷售人員產能提升 | 銷售預測與精準銷售 | 新一代合規質檢
↓ 詳情掃碼訪問官網 rcrai.com

↓ 一鍵關注

