























-620.svg)


循環智能的主動學習(Active Learning)技術探索與實踐:減少 80% 標注量
-

2020-06-09
-

產品 · 技術 · 實踐

但由于需要收集分析的數據量急劇增加,從大量數據中手動提取有用的知識變得非常困難和不可能,因此需要利用自然語言處理(NLP)和數據挖掘(Data Mining)技術來幫助企業挖掘和發現有用的知識。
為了讓機器快速學習,對溝通數據(電話錄音、在線IM溝通記錄)進行標注是必不可少的一步。但是,數據標注需要昂貴的人工或各種成本,面對海量的非結構化數據,如何經濟又準確地進行標注是一個的棘手問題。

主動學習模型的分類
基于流的主動學習,它將未標記的數據一次性全部呈現給一個預測模型,該模型將預測結果(實例的概率值),根據某些評價指標(比如margin)計算評估實例的價值,隨后應用主動學習決定是否應該花費一些預算來收集此數據的類標簽,以進行后續的訓練;
基于池的主動學習,這個通常是離線、反復的過程。這里向主動學習系統提供了大量未標記的數據,在此過程的每個迭代周期,主動學習系統都會選擇一個或者多個未標記數據進行標記并用于隨后的模型訓練,直到預算用盡或者滿足某些停止條件為止。此時,如果預測性能足夠,就可以將模型合并到最終系統中,該最終系統為模型提供未標記的數據并進行預測。
一是僅基于獨立同分布(IID)數據的不確定性進行主動學習,其中選擇標準僅取決于針對每個數據自身信息計算的不確定性值;
二是通過進一步考慮實例相關性來進行主動學習,基于數據相關性的不確定性度量標準,利用一些相似性度量來區分數據之間的差異。
不確定性認為最重要的未標記數據是最接近當前分類邊界的數據;
代表性認為可以表示一組新實例(例如一個聚類)的未標記數據更為重要;
不一致性認為在多個不同基準分類器中具有最大預測差異的未標記數據更為重要。
解決主動學習中類不平衡問題的方法
Zhu和Hovy [1] 等人嘗試在主動學習過程中加入幾種采樣技術,以控制少數類和多數類中被標記實例數量的平衡,他們提出了一個基于bootstrap的過采樣BootOS策略,該策略會基于該樣本的所有k個鄰居生成一個bootstrap樣本。在每次迭代中,選擇不確定性最大的數據進行標記并加入到已標記的數據集中。對應用該過采樣策略來產生更加平衡的數據集,該數據集用于模型的重新訓練。在每次迭代中選擇具有最高不確定性的數據進行標記的操作涉及對已標記的數據進行重采樣和使用重采樣的數據集訓練新的分類器,因此,此方法的可擴展性可能是大型數據集所關注的問題。
Ertekin [2] 等人提出VIRTUAL,一種過采樣和主動學習相結合的方法,它建立了一種對少數群體進行重采樣的自適應技術學習者選擇最有用的樣本進行過采樣,然后該算法沿著的k個鄰居之一的方向構造一個偽樣本。該算法是一個在線算法,且它在構造偽樣本后無需在整個標記數據集上重新訓練就可以逐步構建分類器。 Bloodgood和Shanker [3] 等人利用了代價敏感學習的思想,用于在主動學習過程中處理失衡的數據分布,他們提出一種引入類特定代價的方法,擴展了基于SVM的主動學習的優勢,然后利用經過適當調整的代價敏感的SVM,根據基于不確定性的“margin”標準選擇數據。 Tomanek和Hahn [4] 等人提出了兩種基于不一致顯著性度量的主動學習方法。 Hualong Yu [5] 等人提出了一種基于極限學習機的主動在線加權模型。
真實場景的主動學習策略 LabelXL
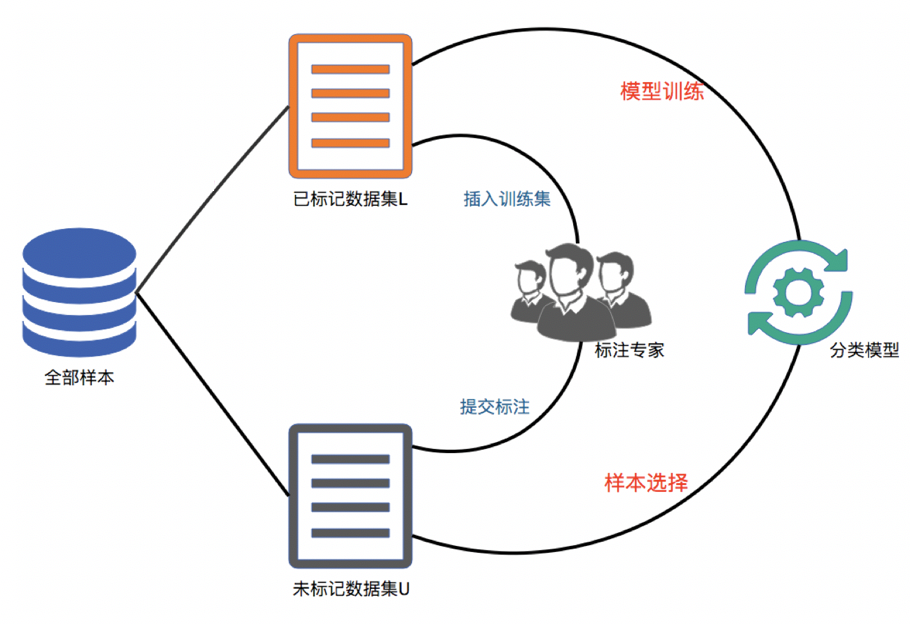

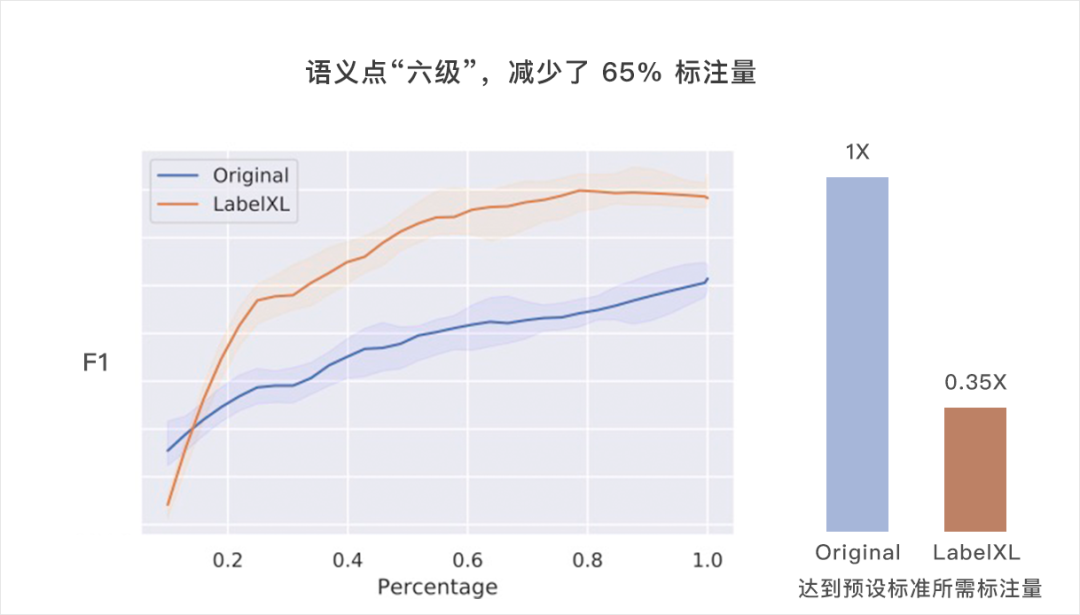
[1] J. Zhu and E. H. Hovy. Active learning for word sense disambiguation with methods for addressing the class imbalance problem. in Proc. EMNLP-CoNLL, 2007, pp. 783–790.
[2] S. Ertekin, J. Huang, and C. L. Giles. Adaptive Resampling with Active Learning. 2009.
[3] M. Bloodgood and K. Vijay-Shanker. Taking into account the differences between actively and passively acquired data: The case of active learning with support vector machines for imbalanced datasets. in Proc. Hum. Lang. Technol., 2009, pp. 137–140.
[4] K. Tomanek and U. Hahn. Reducing class imbalance during active learning for named entity annotation. in Proc. 5th Int. Conf. Knowl. Capture, 2009, pp. 105–112.
[5] H. Yu, X. Yang, S. Zheng, and C. Sun. Active Learning From Imbalanced Data: A Solution of Online Weighted Extreme Learning Machine. IEEE Trans. Neural Netw., vol. 30, no. 4, pp. 1088-1103, Apr. 2019.

產品演示或試用
循環智能
“讓每一次溝通有更好的結果”
線索成單預測 | 銷售執行力監督 | 智能質檢 | 語音識別
> 詳情請訪問官網 rcrai.com

